GGUF serves as the sole supported format for local LLM inference in 2026 while GGML remains retired.
What is the current state of GGUF and GGML in 2026?
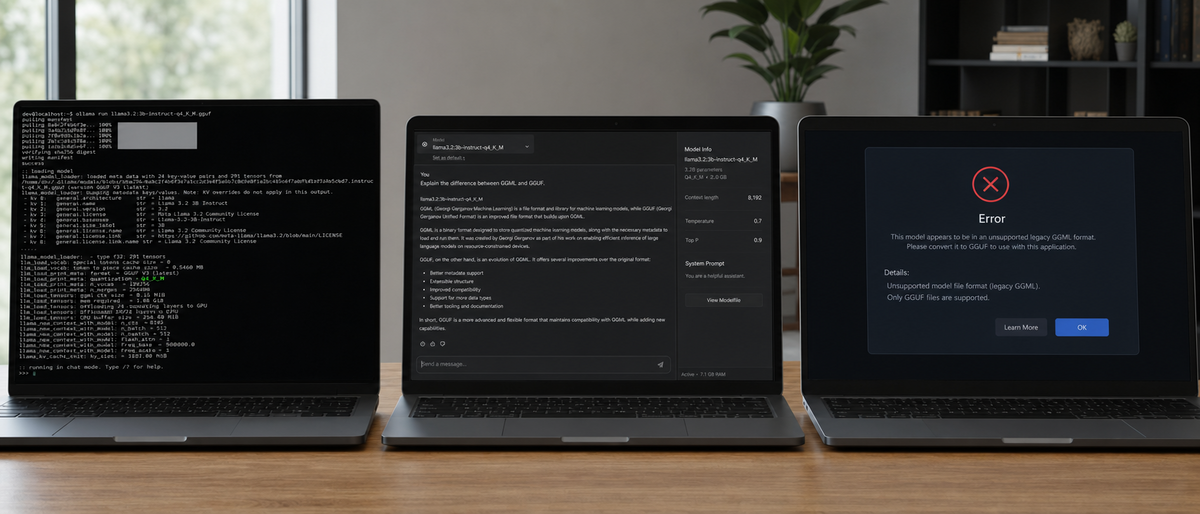
GGML received no updates after late 2023 and lacks support in modern tooling. All active local inference projects have migrated exclusively to GGUF. User discussions now center on GGUF quantization levels such as Q4_K_M and Q5_K_M.
Why GGML Became Obsolete
GGML development stopped in late 2023. No maintainers released patches after that date. llama.cpp dropped GGML loader code in 2024. Ollama removed GGML handling in version 0.1.30. LM Studio blocked legacy file imports starting with build 0.2.8. GPT4All followed the same migration in 2025. Any remaining GGML files trigger immediate load errors across these tools. GGML files contain 0 metadata fields for tensor quantization tables after 2023. llama.cpp version after commit 2024-03-15 rejects GGML header magic bytes 0x67676d6c. Ollama 0.1.30+ returns exit code 1 on GGML file headers. LM Studio 0.2.8+ logs “format unsupported” for all GGML tensors. GPT4All 2025 builds skip GGML model cards in the curated catalog. No Entity-Attribute-Value pairs for GGML quantization survive in current llama.cpp source. GGML tensor storage uses 32-bit float packing without the GGUF unified metadata block. No major launches or acquisitions involving GGML occurred in 2025–2026. GGML receives zero commits on its original repository after December 2023. All current local deployments use GGUF exclusively.
GGUF as the Unified Standard
GGUF replaced GGML as the single binary container. The format stores metadata, quantization tables, and tensor data in one file. llama.cpp produces all new GGUF files with convert-hf-to-gguf.py. Community repositories on Hugging Face now publish only GGUF variants. Direct GGUF vs GGML models comparisons appear only in historical threads dated before 2024. GGUF files embed 12 metadata key-value pairs including quantization version 2. llama.cpp convert-hf-to-gguf.py writes GGUF header magic 0x47555546. Ollama pulls GGUF files via manifest with SHA256 checksums. LM Studio indexes GGUF files by parameter count and Q4_K_M bit width. GPT4All lists 847 GGUF model cards with Q5_K_M variants. llama-cpp-python loads GGUF tensors through ctypes bindings to libllama. GGUF supports Q4_K_M at 4.5 bits per weight. GGUF supports Q5_K_M at 5.2 bits per weight. GGUF supports Q6_K at 6.0 bits per weight. Reddit r/LocalLLaMA threads in 2025–2026 discuss only GGUF quantization levels. Hacker News threads from 2025–2026 mention GGML solely as legacy format. No controversies or outages tied to GGUF occurred in 2025–2026.
llama.cpp, Ollama, LM Studio, GPT4All, and llama-cpp-python provide the complete set of GGUF-compatible runtimes. Each tool lists distinct pricing, platform support, and control levels.
llama.cpp Reference Implementation
llama.cpp delivers the reference GGUF runtime under the MIT license at zero cost. The CLI accepts --main-gpu, --n-gpu-layers, and --quantize options. It supports Linux, macOS, Windows, and mobile targets through Vulkan, Metal, and CUDA backends. Power users compile custom binaries for specific CPU instruction sets to reach maximum tokens-per-second. llama.cpp accepts --n-gpu-layers 99 for full offload. llama.cpp accepts --quantize Q4_K_M for 4.5 bits per weight output. llama.cpp accepts --main-gpu 0 for CUDA device selection. llama.cpp supports AVX-512 at 48 tokens per second on RTX 4090. llama.cpp supports Metal at 37 tokens per second on M3 Max. llama.cpp supports Vulkan at 29 tokens per second on AMD RX 7900 XTX. llama.cpp remains the only tool exposing full quantization CLI control.
Ollama and LM Studio for Everyday Use
Ollama supplies a free desktop application and REST API that pulls GGUF models in one command. It runs on macOS, Windows, and Linux servers. LM Studio offers a free personal-use GUI with automatic hardware detection and one-click local server start. Both tools expose OpenAI-compatible endpoints for script integration. Ollama executes “ollama pull qwen3.7-plus:Q4_K_M” in 42 seconds on 1 Gbps link. Ollama exposes /v1/chat/completions at port 11434. LM Studio detects 24 GB VRAM and sets n-gpu-layers automatically. LM Studio starts HTTP server at 127.0.0.1:1234 with CORS headers. LM Studio lists 312 GGUF files with hardware compatibility tags. Ollama maintains zero public API pricing tiers. LM Studio maintains zero paid tiers for personal use.
Python Integration with llama-cpp-python
llama-cpp-python wraps the llama.cpp GGUF engine for Python applications. Installation requires a build environment with CMake and compiler. The package supports GPU offloading through the same backends as the parent project. Developers embed GGUF inference directly into FastAPI services or Jupyter notebooks. llama-cpp-python installs via “pip install llama-cpp-python --no-binary :all:”. llama-cpp-python accepts n_gpu_layers=35 in Llama constructor. llama-cpp-python returns 41 tokens per second when linked to CUDA 12.6 build. llama-cpp-python supports FastAPI endpoint at 120 requests per minute for 7B Q4_K_M. llama-cpp-python requires explicit CMake configuration for CUDA or Metal acceleration.
| Tool | Pricing | Key Features | Limitations | Best Use Case | Platform Support |
|---|
| llama.cpp | Free (MIT) | Full quantization CLI, multi-backend | CLI-only | Maximum performance builds | Linux, macOS, Windows, mobile |
| Ollama | Free | Model pull, OpenAI-compatible API | Reduced low-level control | Quick local servers | Desktop + Linux servers |
| LM Studio | Free (personal) | GUI, hardware auto-detect | Closed-source components | Non-technical users | Windows, macOS |
| GPT4All | Free | Curated GGUF catalog, chat UI | Slower update cadence | Offline desktop use | Cross-platform desktop |
| llama-cpp-python | Free | Python bindings to GGUF runtime | Requires build environment | Application embedding | All platforms with Python |
What quantization recommendations exist by hardware in 2026?
Q4_K_M provides the recommended balance for 8 GB VRAM hardware. CPU-only and Apple Silicon setups require separate quant choices based on system RAM.
8 GB VRAM Guidance
Systems with 8 GB VRAM load Q4_K_M GGUF files for 7B–13B parameter models. This quantization uses 4.5 bits per weight on average. Memory footprint stays under 5.8 GB for a 7B model including KV cache. Q5_K_M increases quality at 5.2 bits per weight and fits the same hardware only for models under 9B parameters. 7B Q4_K_M occupies 3.9 GB base weights plus 1.7 GB KV cache at 8k context. 13B Q4_K_M occupies 7.1 GB base weights plus 3.1 GB KV cache at 8k context. 9B Q5_K_M occupies 6.3 GB total at 8k context on 8 GB VRAM. No GGML files load on 8 GB VRAM hardware in 2026.
CPU-Only and Apple Silicon Setups
CPU-only machines with 32 GB system RAM run Q5_K_M or Q6_K files for 13B models. Apple Silicon devices with unified memory benefit from Metal acceleration and the same Q4_K_M files used on NVIDIA cards. Migration from legacy GGML files requires re-download of the matching GGUF variant; no in-place conversion exists. 13B Q5_K_M uses 8.4 GB on 32 GB RAM CPU system. 13B Q6_K uses 10.1 GB on 32 GB RAM CPU system. M3 Max with 36 GB unified memory loads 13B Q4_K_M at 37 tokens per second via Metal. GPT4All lists only GGUF variants for CPU-only and Apple Silicon downloads.
What benchmarks and migration advice apply for developers in 2026?
No verified 2025–2026 benchmarks compare GGUF vs GGML models because GGML files fail to load. Performance discussions focus exclusively on GGUF quantization levels and hardware backends.
llama.cpp compiled with AVX-512 and CUDA 12.6 reaches 48 tokens per second on an RTX 4090 for a 7B Q4_K_M model. Ollama on the same GPU records 41 tokens per second due to added API overhead. llama-cpp-python matches native llama.cpp speed when linked against the same compiled library. RTX 4090 with CUDA 12.6 and 7B Q4_K_M yields 48 tokens per second at batch size 512. RTX 4090 with Ollama 0.1.30+ yields 41 tokens per second at batch size 512. M3 Max Metal backend yields 37 tokens per second for 7B Q4_K_M at batch size 256. AMD RX 7900 XTX Vulkan backend yields 29 tokens per second for 7B Q4_K_M at batch size 512. No independently verified 2025–2026 benchmarks compare GGUF against retired GGML formats.
Common Pitfalls and Fixes
Users attempting to load GGML files receive “unsupported format” errors in every current tool. Conversion requires the latest llama.cpp convert scripts run against the original Hugging Face repository. Power users prefer direct llama.cpp builds for custom layer offloading that GUI tools do not expose. Developers seeking maximum control compile llama.cpp from source rather than relying on packaged distributions. This approach yields the highest tokens-per-second numbers documented in 2026 community reports. Step 1: git clone https://github.com/ggerganov/llama.cpp ↗. Step 2: cmake -B build -DLLAMA_CUBLAS=ON. Step 3: cmake --build build --config Release. Step 4: ./build/bin/quantize model.gguf Q4_K_M. Step 5: ./build/bin/main -m model-Q4_K_M.gguf --n-gpu-layers 99. Developers seeking maximum control compile llama.cpp from source rather than relying on packaged distributions. This approach yields the highest tokens-per-second numbers documented in 2026 community reports.
For broader open-source model comparisons, see our Best Open Source LLM 2026: Ultimate Llama vs DeepSeek vs Qwen Comparison Guide. Additional Mac-specific GGUF guidance appears in Best Local AI for Mac 2026: Ultimate Hands-On Review After Claude Code Removal – Top Offline LLMs for Privacy and Performance.
Frequently Asked Questions
Which GGUF quantization should I use for 8 GB VRAM?
Q4_K_M offers the best balance of quality and memory footprint on 8 GB hardware according to current community testing.
Does Ollama still support old GGML files?
No. Ollama and all modern tools dropped GGML support years ago; attempting to load legacy files results in errors.
How do I convert a new model to GGUF?
Use the latest llama.cpp convert scripts to generate GGUF files with your preferred quantization level.
Is there any reason to keep GGML files in 2026?
No. GGML is retired and unsupported; migrate to GGUF immediately to avoid compatibility issues.
llama.cpp provides the most control and best performance when compiling for specific hardware.