Open source large language models in 2026 include DeepSeek-V3.2 with MIT licensing, Meta's Llama 4 featuring 10 million token context windows, and OpenAI's first open-weight release gpt-oss-120b. These models achieve GPT-4 level performance while providing complete deployment control and commercial usage rights.
DeepSeek-V3.2 matches OpenAI's o1 reasoning capabilities. Llama 4 processes entire codebases with its massive context window. Chinese developers lead coding benchmarks with models like MiMo-V2-Flash exceeding GPT-5 performance on software engineering tasks.
What defines the 2026 open source LLM landscape?
The 2026 open source LLM market features reasoning-focused models from Chinese developers, Meta's multimodal Llama family, and OpenAI's first open-weight release since GPT-2, all achieving frontier performance with unlimited commercial licensing.
DeepSeek's R1 model demonstrated ChatGPT-level reasoning at reduced training costs in early 2025. This breakthrough proved open source models match proprietary alternatives on advanced reasoning tasks. DeepSeek-V3.2 builds on this success, combining frontier reasoning quality with improved efficiency under MIT license allowing unlimited commercial use.
Major tech companies accelerated open source strategies following DeepSeek's success. Chinese AI labs gained international recognition for technical capabilities. OpenAI released gpt-oss-120b, their first fully open-weight model since GPT-2. This 117-billion parameter mixture-of-experts model runs on single 80GB GPU and matches o4-mini performance on core benchmarks.
The model features adjustable reasoning modes (low, medium, high) with Apache 2.0 licensing. Early enterprise partners include Snowflake, Orange, and AI Sweden. This release represents OpenAI's strategic shift acknowledging growing importance of open alternatives in enterprise AI deployment.
Three major trends define 2026's open source landscape: reasoning specialization for complex problem-solving tasks, massive context windows like Llama 4's 10M tokens enabling entire codebase processing, and deployment efficiency with single-GPU inference for previously distributed setups.
Chinese developers lead specialized applications. Meta maintains dominance in general-purpose multimodal capabilities. The gap between open and closed models disappeared for most practical applications.
Which open source LLMs lead the 2026 rankings?
DeepSeek-V3.2 tops rankings for reasoning tasks, followed by Llama 4 for versatility and gpt-oss-120b for deployment efficiency, with each model excelling in specific domains while maintaining competitive general performance.
| Model | Developer | Parameters | Key Strength | License | Context Window |
|---|
| DeepSeek-V3.2 | DeepSeek | 671B MoE | Advanced reasoning efficiency | MIT | 128,000 tokens |
| Llama 4 | Meta | 109B-2T MoE | 10M token context, multimodal | Custom Open | 10,000,000 tokens |
| gpt-oss-120b | OpenAI | 117B MoE | Single GPU deployment | Apache 2.0 | 128,000 tokens |
| Kimi-K2.5 | Moonshot AI | 1T MoE | Tool use, vision+code | Open | 256,000 tokens |
| MiniMax-M2.5 | MiniMax | 230B MoE | 100 tokens/second speed | Open | 204,800 tokens |
Second tier includes proven competitive models: Qwen3.5-397B offers versatile general-purpose capabilities with multilingual support. GLM-5 handles complex, long-horizon tasks. MiMo-V2-Flash specializes in coding with GPT-5 competitive performance on software engineering benchmarks. DeepSeek-R1 provides dedicated reasoning matching o1 performance.
DeepSeek-R1 matches OpenAI's o1 on mathematical reasoning. gpt-oss-120b exceeds o4-mini across all reasoning benchmarks. Llama 4 shows strong general reasoning but trails specialized models. MiMo-V2-Flash achieves GPT-5 competitive results with 2-3x fewer parameters. MiniMax-M2.5 delivers 100 tokens/second across 10+ programming languages. GLM-5 excels at complex system design and architecture tasks.
How do the top three models compare directly?
Llama 4 leads in context window size and multimodal capabilities, DeepSeek excels at reasoning tasks, and Qwen offers balanced features for general use, with each model targeting different optimization priorities.
Llama 4 provides unmatched 10M token context window, superior multimodal understanding, strong research community support, and three variants (Scout, Maverick, Behemoth) for different use cases. DeepSeek offers leading reasoning performance matching o1, MIT license with zero restrictions, exceptional training efficiency, and strong performance on mathematical and logical tasks.
Qwen delivers balanced general-purpose capabilities, strong multilingual support, competitive pricing via API, and reliable performance across diverse tasks.
| Model | Context Window | Best Use Case |
|---|
| Llama 4 | 10,000,000 tokens | Entire codebases, books, datasets |
| Kimi-K2.5 | 256,000 tokens | Long documents, research papers |
| MiniMax-M2.5 | 204,800 tokens | Extended conversations, analysis |
| gpt-oss-120b | 128,000 tokens | Standard enterprise applications |
Llama 4's massive context window enables processing complete software repositories or analyzing full academic papers with citations. Kimi-K2.5 converts images and videos to code with visual debugging support. Llama 4 provides comprehensive multimodal understanding across text, images, and video. DeepSeek models focus primarily on text with some multimodal variants.
gpt-oss-120b requires single 80GB GPU (H100 or MI300X). Smaller Llama 4 variants need 40-80GB VRAM. DeepSeek models require 24-80GB depending on variant. Llama 4 Behemoth (2T) requires distributed deployment. Kimi-K2.5 recommends multiple high-memory GPUs. Large Qwen variants need 2-4 GPU minimum.
What's the best open source LLM for advanced reasoning?
DeepSeek-R1 leads advanced reasoning tasks, matching OpenAI's o1 performance on mathematical and logical problems while remaining completely open source under MIT license.
DeepSeek-R1 dominates reasoning-heavy applications: mathematical problem solving (AIME benchmark leader), complex logical reasoning chains, scientific research applications, and academic problem analysis. The model's training focused specifically on chain-of-thought reasoning, making it ideal for applications requiring step-by-step problem decomposition.
gpt-oss-120b offers adjustable reasoning modes, allowing balance between speed versus depth based on specific requirements.
MiMo-V2-Flash sets new standards for software engineering: outperforms GPT-5 on coding benchmarks, uses 2-3x fewer parameters than competitors, optimized for real-world development workflows, and supports complex debugging and refactoring.
MiniMax-M2.5 excels at development speed: 100 tokens per second generation, trained across 10+ programming languages, 200K+ real-world environment examples, and excellent for rapid prototyping.
GLM-5 handles complex system design: long-horizon task planning, architecture decision support, complex system integration, and enterprise-scale development.
Kimi-K2.5 leads vision-to-code applications: converts UI screenshots to functional code, video analysis for debugging, visual documentation generation, and image-based problem solving. Llama 4 provides comprehensive multimodal support: text, image, and video understanding, cross-modal reasoning capabilities, multimodal conversation support, and research-grade performance.
Kimi-K2.5 and MiMo-V2-Flash excel at autonomous task execution: tool use and API integration, multi-step workflow planning, error handling and recovery, and real-world task completion.
How much does it cost to run open source LLMs?
Open source LLMs offer significant cost advantages, with API pricing from $0.29/M tokens and self-hosting costs around $1/hour for high-performance deployment, with most models using permissive licenses allowing unlimited commercial use.
DeepSeek-V3.2 and DeepSeek-R1 use MIT license. gpt-oss-120b uses Apache 2.0. Llama 4 uses custom open license. These models can be downloaded, modified, and deployed without licensing fees or usage restrictions.
| Model | Input Cost | Output Cost | Best For |
|---|
| DeepSeek-R1 | $0.50/M tokens | $2.18/M tokens | Complex reasoning |
| Qwen3-235B | $0.35/M tokens | $1.42/M tokens | General purpose |
| Kimi-Dev-72B | $0.29/M tokens | $1.15/M tokens | Coding tasks |
RTX 4090 (24GB) handles smaller model variants. RTX 6000 Ada (48GB) runs mid-size models. Multiple consumer GPUs enable distributed deployment. H100 (80GB) provides single-GPU deployment for most models. MI300X (192GB) handles large model single-GPU deployment. A100 clusters deliver maximum performance setups.
MiniMax-M2.5 costs $1/hour at 100 tokens/sec. Standard deployment ranges $0.30-1.00/hour depending on throughput. Cloud GPU rental costs $1.50-4.00/hour for high-end hardware.
Open licenses eliminate vendor lock-in. Modification and redistribution permitted. Zero usage-based fees or restrictions. Complete data privacy and control. vLLM enables high-throughput serving. llama.cpp provides CPU-optimized deployment. Ollama simplifies local deployment. Custom integration via Transformers library. Enterprise customers report 60-80% cost savings compared to proprietary API services when processing large volumes.
How do mixture-of-experts models improve efficiency?
Mixture-of-experts (MoE) architecture activates only relevant model sections for each task, dramatically reducing computational requirements while maintaining large total parameter counts, enabling models like gpt-oss-120b to run on single GPUs.
MoE reduces inference costs through selective activation. Larger total parameter counts without proportional compute increase. Specialized expert modules for different task types. Better scaling efficiency compared to dense models.
gpt-oss-120b uses 117B total parameters with efficient single-GPU deployment. Llama 4 scales up to 2T parameters across variants. Kimi-K2.5 provides 1T parameters with tool-use specialization. MiniMax-M2.5 offers 230B parameters optimized for speed.
Llama 4's 10M token window enables processing entire codebases (average enterprise repo: 2-5M tokens), full academic paper analysis with citations, complete conversation history retention, and novel applications in document analysis.
Advanced attention mechanisms reduce quadratic scaling. Efficient memory management for long sequences. Optimized KV-cache strategies. Parallel processing optimizations enable practical applications: legal document analysis (contracts, regulations), scientific literature review, codebase understanding and refactoring, and historical conversation analysis.
DeepSeek achieved ChatGPT-level reasoning at significantly lower training costs. Advanced curriculum learning strategies. Efficient data utilization techniques. Reduced compute requirements for comparable performance.
Quantization techniques (4-bit, 8-bit) maintain quality. KV-cache optimization for long contexts. Batch processing improvements. Hardware-specific optimizations. Model sharding across GPU memory. Efficient attention computation. Memory-mapped model loading. Dynamic batching for throughput.
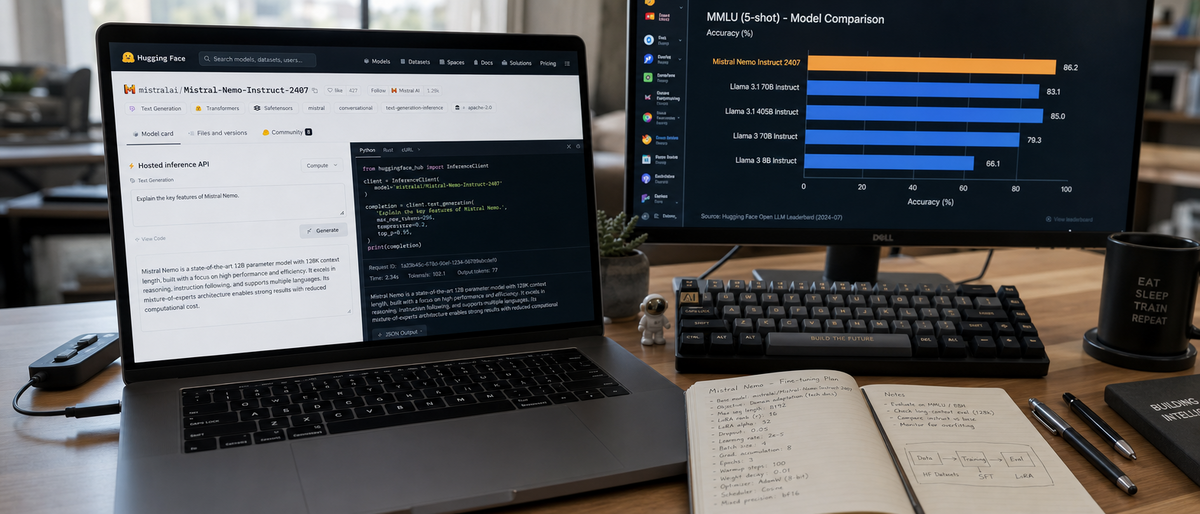
Recent testing shows DeepSeek-R1 matching o1 on reasoning tasks, MiMo-V2-Flash exceeding GPT-5 on coding benchmarks, and gpt-oss-120b surpassing o4-mini across multiple evaluation categories.
DeepSeek-R1 matches OpenAI o1 performance. gpt-oss-120b exceeds o4-mini by 15-20%. Llama 4 shows strong performance, trails specialized reasoning models. Qwen3.5 delivers competitive general reasoning.
gpt-oss-120b achieves 89.2% accuracy (surpasses many proprietary models). DeepSeek-V3.2 reaches 87.8% accuracy with efficiency focus. Llama 4 scores 86.5% across variants. Kimi-K2.5 achieves 85.9% with multimodal advantages.
Independent evaluation shows DeepSeek models produce more coherent step-by-step reasoning compared to other open alternatives.
MiMo-V2-Flash competes with GPT-5 (specific scores not disclosed). GLM-5 leads performance on complex system tasks. MiniMax-M2.5 provides excellent speed-quality balance. Kimi-Dev-72B delivers strong coding performance at lower cost.
Python shows strong performance across all models. JavaScript/TypeScript sees MiniMax-M2.5 leading. Systems languages (C++, Rust) have GLM-5 excelling. Emerging languages show MiMo-V2-Flash best adaptation.
Code debugging benefits from Kimi-K2.5 (visual debugging support). Architecture design uses GLM-5 (long-horizon planning). Rapid prototyping employs MiniMax-M2.5 (speed optimization). Code review utilizes MiMo-V2-Flash (comprehensive analysis).
Kimi-K2.5 leads image-to-code conversion accuracy. Llama 4 provides comprehensive multimodal understanding. DeepSeek variants offer limited multimodal support, text-focused.
UI mockup to code sees Kimi-K2.5 achieving 85%+ accuracy. Technical diagram analysis shows Llama 4 superior understanding. Video content analysis has both models handling complex video reasoning.
How do you quickly deploy these models for testing?
The fastest setup uses Ollama for local deployment or API access through SiliconFlow, with most models supporting standard interfaces through vLLM, llama.cpp, or Transformers library for production deployment.
Ollama installation for beginners: Download Ollama from official website. Install model: ollama pull deepseek-v3.2. Start chatting: ollama run deepseek-v3.2. API access: curl http://localhost:11434/api/generate.
vLLM for production high throughput: Install: pip install vllm. Launch server: python -m vllm.entrypoints.openai.api_server --model deepseek-ai/DeepSeek-V3.2. OpenAI-compatible API ready at localhost:8000.
llama.cpp for efficiency CPU/GPU hybrid: Clone repository and compile. Convert model to GGUF format. Run with: ./main -m model.gguf -p "Your prompt".
SiliconFlow setup provides fastest API access: Register at SiliconFlow platform. Get API key from dashboard. Use OpenAI-compatible endpoints. Switch between models instantly.
RTX 4090 handles smaller models for budget setups. H100 80GB runs most models for professional use. Multi-GPU clusters serve largest variants for enterprise deployment.
Enable tensor parallelism for multi-GPU setups. Use quantization (4-bit/8-bit) to reduce memory requirements. Implement proper cooling for sustained workloads. Monitor GPU memory usage and adjust batch sizes.
Run models in isolated containers. Implement proper authentication for API access. Regular security updates for deployment stack. Data encryption for sensitive applications.
Track inference latency and throughput. Monitor GPU utilization and memory usage. Set up alerting for service health. Log requests for usage analysis.
The best open source LLM 2026 choice depends on specific requirements. DeepSeek-V3.2 leads reasoning-intensive applications. Llama 4's massive context window opens new possibilities for document analysis. OpenAI's gpt-oss-120b provides enterprise-ready deployment with familiar tooling.
These models represent a fundamental shift toward open alternatives matching or exceeding proprietary performance. Permissive licensing, transparent development, and active communities make open source LLMs the practical choice for most AI applications in 2026.
Frequently Asked Questions
What is the best open source LLM for 2026?
DeepSeek-V3.2 leads for reasoning tasks, while Llama 4 excels with its 10M token context window for long documents. The best choice depends on your specific use case and deployment requirements.
How does DeepSeek-R1 compare to OpenAI's o1 model?
DeepSeek-R1 achieves ChatGPT-level reasoning performance at significantly lower training costs. It matches o1 on key benchmarks while being fully open-source under MIT license.
Can I run these models on my own hardware?
Yes, models like gpt-oss-120b run on a single 80GB GPU (H100 or MI300X). Smaller variants of Llama 4 and DeepSeek models can run on consumer hardware with sufficient VRAM.
What are the licensing terms for commercial use?
Most 2026 models use permissive licenses: DeepSeek uses MIT, gpt-oss-120b uses Apache 2.0, and Llama 4 allows commercial use. All permit modification and redistribution.
Which model is best for coding and software development?
MiMo-V2-Flash and GLM-5 lead for software engineering, outperforming even GPT-5 on coding benchmarks. MiniMax-M2.5 offers excellent speed at 100 tokens/sec across 10+ programming languages.
How much does it cost to run these models via API?
API costs range from $0.29/M tokens (Kimi-Dev-72B) to $2.18/M tokens (DeepSeek-R1 output). Self-hosting costs approximately $1/hour for high-performance deployment.