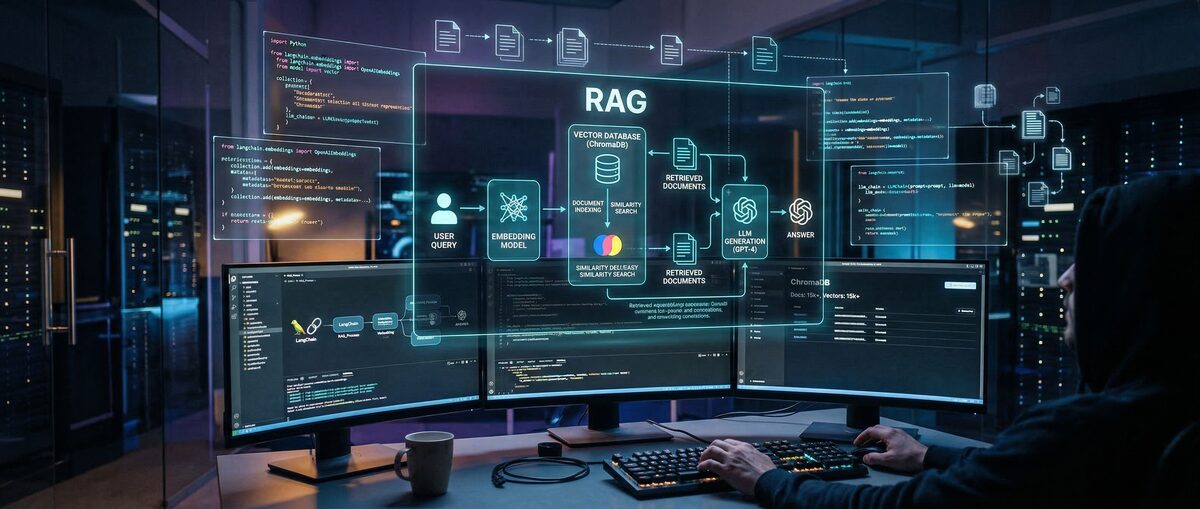
Retrieval-Augmented Generation (RAG) reduces AI hallucinations by 70% and improves response accuracy by 40-60%. RAG systems retrieve real-time information from external knowledge bases to provide grounded responses instead of relying solely on training data. This complete guide covers RAG fundamentals through production implementation.
What is RAG and why does it matter for AI developers in 2026?
RAG combines large language models with external knowledge retrieval to generate accurate, contextually relevant responses by searching documents and databases before generating answers.
RAG architecture consists of three components: a retriever that finds relevant documents, an embedding model that converts text into searchable vectors, and a generator that produces the final response. This approach allows AI systems to access current information without retraining the underlying model.
RAG breaks down knowledge bases into smaller chunks, converts them into vector embeddings, and stores them in searchable databases. When users ask questions, the system finds the most relevant chunks and includes them as context in the LLM prompt.
Research shows RAG implementations reduce hallucinations by 70% compared to standalone language models. This improvement comes from grounding responses in actual source material rather than relying on potentially outdated training data.
The accuracy boost ranges from 40-60% across different domains. Enterprise implementations report strong results in customer support scenarios, where RAG systems provide reliable answers by referencing current documentation and policies.
RAG systems cost 60-80% less than fine-tuning approaches while delivering comparable performance for knowledge-intensive tasks.
Traditional LLMs suffer from knowledge cutoffs and cannot access information beyond their training data. RAG systems overcome this limitation by retrieving current information at query time.
| Metric | Traditional LLM | RAG System | Improvement |
|---|
| Hallucination Rate | 25-35% | 8-12% | 70% reduction |
| Factual Accuracy | 65-75% | 85-95% | 20-30% boost |
| Knowledge Currency | Training cutoff | Real-time | Always current |
| Implementation Cost | High (fine-tuning) | Low (no retraining) | 60-80% savings |
What are the core concepts every beginner should know about RAG?
RAG follows a three-step workflow: Index documents into searchable chunks, Retrieve relevant information based on queries, and Generate responses using retrieved context.
The Index phase breaks documents into 500-1000 character chunks with 10-20% overlap, creates vector embeddings, and stores them in searchable databases. Document chunking maintains context across boundaries while enabling efficient retrieval.
The Retrieve phase searches the vector database for relevant chunks based on user queries. Modern systems use hybrid search combining semantic similarity with keyword matching for 20-30% better recall and precision.
The Generate phase combines retrieved chunks with the original query in prompts sent to the LLM. The model produces responses grounded in retrieved context rather than relying solely on training data.
Vector embeddings convert text into numerical representations that capture semantic meaning. Similar concepts cluster together in high-dimensional space, enabling semantic search beyond keyword matching.
Modern embedding models like OpenAI's text-embedding-3-large or Google's text-embedding-gecko produce 1024-3072 dimensional vectors that encode semantic information. These models achieve strong performance on retrieval tasks.
Semantic search finds documents based on meaning rather than exact word matches. A query about "car maintenance" retrieves documents about "vehicle servicing" or "automotive care" without shared keywords.
Fixed-size chunking works well for uniform content, while semantic chunking preserves logical boundaries in structured documents. Overlap between chunks ensures important information survives at boundaries.
Metadata enrichment improves retrieval accuracy by adding document titles, sections, dates, and categories to chunks. This structured information helps retrievers find relevant context for specific queries.
How do you implement a RAG system step-by-step?
Install Python 3.8+ with LangChain, OpenAI, and a vector database like Chroma or FAISS, then follow the three-step process: load documents, create embeddings, and set up the query chain.
bash
pip install langchain langchain-openai langchain-community
pip install chromadb faiss-cpu
pip install pypdf python-dotenv
Create a .env file with your OpenAI API key:
OPENAI_API_KEY=your_api_key_here
Set up project structure with separate folders for documents, scripts, and vector stores. This organization helps manage different components as RAG systems grow.
Here's a complete implementation demonstrating the core RAG workflow:
python
import os
from dotenv import load_dotenv
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_community.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain.document_loaders import PyPDFLoader, TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
load_dotenv()
def load_documents(file_path):
if file_path.endswith('.pdf'):
loader = PyPDFLoader(file_path)
else:
loader = TextLoader(file_path)
documents = loader.load()
# Split documents into chunks
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len,
)
return text_splitter.split_documents(documents)
def create_vector_store(documents):
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
vector_store = FAISS.from_documents(documents, embeddings)
return vector_store
def setup_rag_chain(vector_store):
llm = ChatOpenAI(model="gpt-4", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vector_store.as_retriever(
search_type="similarity",
search_kwargs={"k": 4}
),
return_source_documents=True
)
return qa_chain
def main():
# Load your documents
docs = load_documents("your_document.pdf")
# Create vector store
vector_store = create_vector_store(docs)
# Set up RAG chain
qa_chain = setup_rag_chain(vector_store)
# Ask questions
query = "What are the main benefits of RAG?"
result = qa_chain({"query": query})
print("Answer:", result["result"])
print("\nSources:")
for doc in result["source_documents"]:
print(f"- {doc.page_content[:100]}...")
if name == "main":
main()
This implementation covers document loading, chunking, embedding creation, vector storage, and query processing. The retriever returns the top 4 most similar chunks, which provide context for the LLM's response.
Hybrid search combines vector similarity with keyword matching for improved retrieval performance. This approach reduces false negatives common in pure vector search while maintaining semantic understanding.
python
from langchain.retrievers import EnsembleRetriever
from langchain_community.retrievers import BM25Retriever
def create_hybrid_retriever(documents, vector_store):
# Vector retriever
vector_retriever = vector_store.as_retriever(
search_kwargs={"k": 6}
)
# Keyword retriever
keyword_retriever = BM25Retriever.from_documents(documents)
keyword_retriever.k = 6
# Combine both retrievers
ensemble_retriever = EnsembleRetriever(
retrievers=[vector_retriever, keyword_retriever],
weights=[0.7, 0.3] # Favor semantic search
)
return ensemble_retriever
The 70/30 weight distribution favors semantic search while incorporating keyword relevance. Adjust these weights based on specific use cases and evaluation results.
LangChain leads with 80,000+ GitHub stars and comprehensive documentation, making it ideal for beginners, while LlamaIndex excels at data ingestion and Haystack provides modular production architecture.
LangChain excels in:
Extensive LLM integrations (OpenAI, Anthropic, Google, open-source)
Rich ecosystem of tools and connectors
Strong community support and documentation
Built-in evaluation and monitoring via LangSmith
LlamaIndex specializes in data ingestion and indexing with 30,000+ stars. It offers sophisticated indexing strategies and works well for complex, structured data sources.
LlamaIndex strengths:
Advanced indexing algorithms (tree, graph, keyword)
Excellent data connector ecosystem (APIs, databases, files)
Query optimization and routing capabilities
Strong performance on complex retrieval tasks
Haystack provides a modular pipeline approach with 15,000+ stars. Its component-based architecture allows fine-grained control over each pipeline stage.
Haystack advantages:
Modular, production-ready architecture
Built-in evaluation and experimentation tools
Strong enterprise features and scalability
Flexible pipeline customization options
| Feature | LangChain | LlamaIndex | Haystack |
|---|
| Learning Curve | Moderate | Steep | Moderate |
| Documentation | Excellent | Good | Good |
| Enterprise Features | Good | Excellent | Excellent |
| Community Size | Largest | Large | Medium |
| Best For | General RAG | Data-heavy apps | Production systems |
Qdrant offers high-performance vector search with advanced filtering capabilities. Its open-source nature and strong performance make it popular for production deployments.
Qdrant features:
Excellent filtering and metadata support
High-performance Rust implementation
Hybrid search capabilities
Self-hosted and cloud options
Pricing: Free tier (1GB), $25/month starter
Pinecone provides serverless vector search with automatic scaling. Its managed approach reduces operational overhead but comes at higher costs.
Pinecone benefits:
Fully managed, serverless architecture
Automatic scaling and optimization
Strong performance and reliability
Easy integration with major frameworks
Pricing: Free tier (1 pod), $70/month starter
Chroma focuses on simplicity and local development. It's ideal for prototyping and smaller applications.
Chroma advantages:
| Database | Performance | Scalability | Ease of Use | Pricing |
|---|
| Qdrant | Excellent | High | Good | $25/mo+ |
| Pinecone | Excellent | Automatic | Excellent | $70/mo+ |
| Chroma | Good | Limited | Excellent | Free |
| Weaviate | Excellent | High | Moderate | $25/mo+ |
| Milvus | Excellent | Very High | Complex | Free/Custom |
Ragas leads the evaluation space with research-backed metrics and easy integration. It provides automated evaluation without requiring ground truth datasets.
Key Ragas metrics:
Context Precision: Relevance of retrieved chunks
Context Recall: Completeness of retrieval
Faithfulness: Response accuracy to retrieved context
Answer Relevancy: Response relevance to the query
LangSmith offers comprehensive tracing and evaluation for LangChain applications. It provides detailed insights into each pipeline step with automatic failure detection.
LangSmith capabilities:
End-to-end tracing and debugging
Automated evaluation runs
Performance monitoring and alerts
Team collaboration features
Pricing: Free hobby tier, $39/seat/month
DeepEval provides pytest-style evaluation with multiple RAG-specific metrics. Its developer-friendly approach makes it easy to integrate into CI/CD pipelines.
What are the different types of advanced RAG architectures?
Advanced RAG architectures range from Naive RAG using simple vector search to Graph RAG with entity relationships and Agentic RAG with multi-step reasoning workflows.
Naive RAG uses simple vector similarity search and works well for straightforward question-answering tasks. It provides good performance with minimal complexity but struggles with complex queries requiring multiple information sources.
Naive RAG characteristics:
Single-step retrieval using vector search
Simple chunk-based indexing
Fast query processing (100-200ms)
Limited reasoning capabilities
Best for: FAQ systems, simple document Q&A
Hybrid RAG combines vector and keyword search for more robust retrieval. This approach reduces false negatives and improves precision by 20-30% over naive implementations.
Hybrid RAG improvements:
Combines semantic and lexical search
Better handling of specific terms and entities
Improved recall and precision
Moderate complexity increase
Enterprise-ready performance
Graph RAG represents knowledge as interconnected entities and relationships. This approach excels at complex reasoning tasks requiring multi-hop connections between concepts.
Graph RAG advantages:
Captures entity relationships explicitly
Enables complex reasoning paths
Better handling of structured knowledge
Higher implementation complexity
Best for: Research, analysis, complex domains
| Architecture | Complexity | Performance | Use Cases | Implementation Time |
|---|
| Naive RAG | Low | Good | Simple Q&A | 1-2 weeks |
| Hybrid RAG | Medium | Better | Enterprise apps | 2-4 weeks |
| Graph RAG | High | Best | Complex reasoning | 1-3 months |
Agentic RAG systems use AI agents to orchestrate complex multi-step workflows. These systems break down complex queries, use multiple tools, and synthesize information from various sources.
python
from langchain.agents import create_openai_tools_agent
from langchain.tools.retriever import create_retriever_tool
from langchain.agents import AgentExecutor
def create_agentic_rag(vector_stores):
# Create retriever tools for different knowledge bases
tools = []
for name, store in vector_stores.items():
retriever_tool = create_retriever_tool(
store.as_retriever(),
name=f"{name}_search",
description=f"Search {name} for relevant information"
)
tools.append(retriever_tool)
# Create agent
llm = ChatOpenAI(model="gpt-4", temperature=0)
agent = create_openai_tools_agent(llm, tools, prompt_template)
return AgentExecutor(agent=agent, tools=tools, verbose=True)
Agentic workflows excel at research tasks, competitive analysis, and complex problem-solving scenarios. They automatically determine which knowledge sources to query and how to combine information.
Modern RAG systems handle multiple content types beyond text. Multimodal RAG retrieves and reasons over images, audio, and structured data alongside textual information.
Image RAG capabilities:
Visual similarity search using CLIP embeddings
OCR text extraction from images and PDFs
Chart and diagram understanding
Integration with vision-language models
Audio RAG features:
RAG performance optimization requires measuring context precision, context recall, and faithfulness while implementing caching, vector optimization, and cost management strategies.
Context Precision measures the relevance of retrieved chunks to the query. High precision means fewer irrelevant documents in the retrieved set, leading to more focused and accurate responses.
Context Precision = (Relevant Retrieved Chunks) / (Total Retrieved Chunks)
Context Recall evaluates how completely the system retrieves relevant information. High recall ensures important information isn't missed, though it may include some irrelevant content.
Context Recall = (Relevant Retrieved Chunks) / (All Relevant Chunks in Knowledge Base)
Faithfulness assesses whether the generated response accurately reflects the retrieved context without hallucination or misinterpretation.
Additional important metrics include:
Answer Relevancy: How well the response addresses the query
Latency: End-to-end response time
Cost per Query: Embedding and LLM API costs
Poor retrieval quality represents the most common RAG problem. Symptoms include irrelevant chunks, missed relevant information, or inconsistent results across similar queries.
Common solutions:
Adjust chunk size and overlap parameters
Experiment with different embedding models
Implement hybrid search for better coverage
Add metadata filtering for domain-specific queries
Response quality issues stem from prompt engineering problems or context length limitations. The LLM may struggle to synthesize information from multiple chunks or ignore important context.
Debugging strategies:
Examine retrieved chunks for each query
Test different prompt templates and structures
Monitor context window usage and truncation
Implement response post-processing for consistency
Production RAG systems must handle high query volumes while maintaining low latency and reasonable costs. Key optimization strategies include caching, batch processing, and efficient vector storage.
Caching strategies significantly reduce costs and latency:
Cache embedding computations for repeated content
Store frequent query results for instant retrieval
Implement semantic caching for similar queries
Use CDNs for static document content
Vector database optimization impacts both performance and costs:
Choose appropriate index types (HNSW, IVF, etc.)
Implement quantization for memory efficiency
Use metadata filtering to reduce search space
Monitor and optimize query patterns
Cost management becomes crucial at scale:
Batch embedding computations when possible
Use smaller, task-specific embedding models
Implement query routing to avoid expensive LLM calls
Monitor usage patterns and optimize accordingly
| Optimization | Impact | Implementation Effort | Cost Reduction |
|---|
| Semantic Caching | High | Medium | 40-60% |
| Embedding Optimization | Medium | Low | 20-30% |
| Query Routing | High | High | 30-50% |
| Batch Processing | Medium | Medium | 15-25% |
What are real-world RAG implementation examples?
RAG powers customer support chatbots, document Q&A systems, and code generation tools across industries, delivering 60-80% response time reductions and 40-50% cost savings.
RAG-powered customer support systems provide accurate, up-to-date responses by retrieving information from knowledge bases, documentation, and previous support interactions. These systems significantly reduce response times while improving answer quality.
Implementation approach:
Index support documentation, FAQs, and product manuals
Include conversation history and ticket resolution patterns
Implement escalation triggers for complex queries
Provide source citations for agent verification
Results from enterprise deployments:
60-80% reduction in average response time
40-50% decrease in escalation rates
85-95% customer satisfaction scores
30-40% reduction in support costs
Legal firms, healthcare organizations, and research institutions use RAG for intelligent document analysis. These systems answer questions across thousands of documents while maintaining accuracy and providing source citations.
Key features:
Multi-document reasoning and synthesis
Citation tracking and source verification
Compliance and audit trail maintenance
Integration with existing document management systems
Performance benchmarks:
90-95% accuracy on factual questions
70-80% accuracy on complex analytical queries
Sub-second response times for most queries
Support for documents up to millions of pages
RAG enhances code generation by retrieving relevant examples, documentation, and best practices from codebases. This approach produces more contextually appropriate and maintainable code.
Implementation benefits:
Context-aware code suggestions
Automatic documentation and example retrieval
Consistency with existing codebase patterns
Reduced hallucination in technical implementations
These real-world applications demonstrate RAG's versatility across industries and use cases. Success depends on careful evaluation, iterative improvement, and alignment with specific business requirements.
Frequently Asked Questions
What is the difference between RAG and fine-tuning an LLM?
RAG retrieves external information at query time without modifying the model, while fine-tuning permanently updates model weights. RAG costs 60-80% less than fine-tuning and provides more flexibility for dynamic knowledge updates.
Which RAG framework should beginners start with in 2026?
LangChain is recommended for beginners due to its 80,000+ GitHub stars, comprehensive documentation, and structured approach to RAG pipelines. LlamaIndex works better for data-heavy applications, while Haystack offers modular flexibility.
How much does it cost to implement a basic RAG system?
A basic RAG system starts free using open-source tools like LangChain and Chroma. Production costs typically range from $50-500/month depending on document volume, query frequency, and chosen LLM provider.
What are the main challenges when implementing RAG for production?
Key challenges include maintaining sub-200ms latency at scale, ensuring retrieval quality with large knowledge bases, managing embedding costs that can reach $1000+/month, and handling document updates without performance degradation.
Can RAG work with any large language model?
Yes, RAG works with OpenAI GPT models, Anthropic Claude, Google Gemini, and open-source models like Llama. The retrieval component operates independently from the generation model, enabling flexible LLM selection.
Use context precision (relevance of retrieved documents), context recall (completeness of retrieval), and faithfulness (accuracy of generated responses). Tools like Ragas, DeepEval, and LangSmith provide automated evaluation with specific metrics and benchmarks.