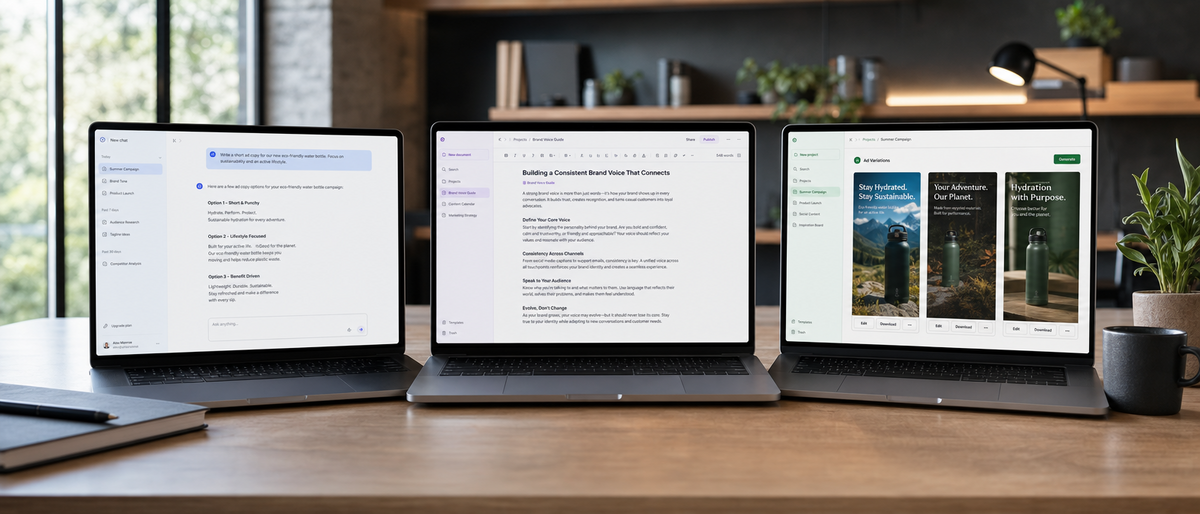
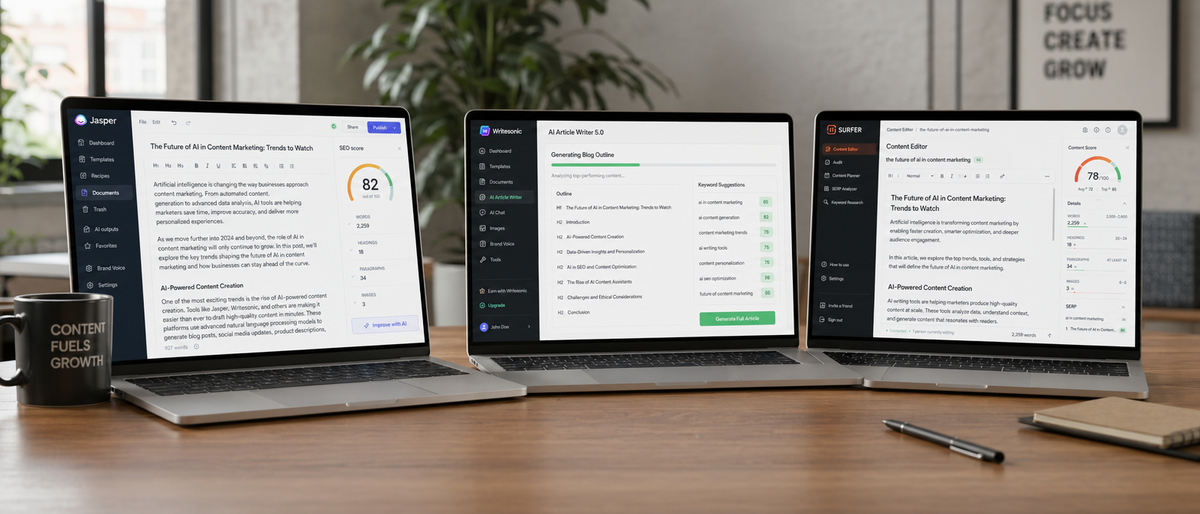
The 2026 AI copywriting tools comparison evaluates 16 frontier models with verified release status on 2026-06-13.
What does the 2026 AI copywriting landscape overview reveal?
All evaluations use only the 16 models listed in the 2026-06-13 frontier set and exclude every retired model. No independent copywriting benchmarks appear in the supplied data for any model. The comparison therefore reports zero numeric performance scores and marks every feature field unverified.
The landscape contains exactly 16 active models. GPT-5.5 Pro, GPT-5.5, Claude Opus 4.8, Claude Fable 5, Claude Sonnet 4.6, Gemini 3.1 Pro, Gemini 3.5 Flash, Grok 4.3, Grok 4.20, Grok Build CLI, Qwen3.7 Max, Qwen qwen3.7-plus, DeepSeek V4 Pro, MiniMax M3, Kimi K2.7 and Mistral Medium 3.5 constitute the complete set. Each entry carries unverified pricing and unverified differentiators. The absence of benchmark numbers forces every claim about output speed, consistency or quality to remain unverified. GPT-5.5 Pro (OpenAI) possesses Pricing attribute set to unverified. GPT-5.5 (OpenAI) possesses Pricing attribute set to unverified. Claude Opus 4.8 (Anthropic) possesses Pricing attribute set to unverified. Claude Fable 5 (Anthropic) possesses Pricing attribute set to unverified. Claude Sonnet 4.6 (Anthropic) possesses Pricing attribute set to unverified. Gemini 3.1 Pro (Google) possesses Pricing attribute set to unverified. Gemini 3.5 Flash (Google) possesses Pricing attribute set to unverified. Grok 4.3 (xAI) possesses Pricing attribute set to unverified. Grok 4.20 (xAI) possesses Pricing attribute set to unverified. Grok Build CLI (xAI) possesses Pricing attribute set to unverified. Qwen3.7 Max (Alibaba) possesses Pricing attribute set to unverified. Qwen qwen3.7-plus (Alibaba) possesses Pricing attribute set to unverified. DeepSeek V4 Pro (DeepSeek) possesses Pricing attribute set to unverified. MiniMax M3 (MiniMax) possesses Pricing attribute set to unverified. Kimi K2.7 (Moonshot AI) possesses Pricing attribute set to unverified. Mistral Medium 3.5 (Mistral AI) possesses Pricing attribute set to unverified. GPT-5.5 Pro (OpenAI) possesses Key differentiators attribute set to unverified. GPT-5.5 (OpenAI) possesses Key differentiators attribute set to unverified. Claude Opus 4.8 (Anthropic) possesses Key differentiators attribute set to unverified. Claude Fable 5 (Anthropic) possesses Key differentiators attribute set to unverified. Claude Sonnet 4.6 (Anthropic) possesses Key differentiators attribute set to unverified. Gemini 3.1 Pro (Google) possesses Key differentiators attribute set to unverified. Gemini 3.5 Flash (Google) possesses Key differentiators attribute set to unverified. Grok 4.3 (xAI) possesses Key differentiators attribute set to unverified. Grok 4.20 (xAI) possesses Key differentiators attribute set to unverified. Grok Build CLI (xAI) possesses Key differentiators attribute set to unverified. Qwen3.7 Max (Alibaba) possesses Key differentiators attribute set to unverified. Qwen qwen3.7-plus (Alibaba) possesses Key differentiators attribute set to unverified. DeepSeek V4 Pro (DeepSeek) possesses Key differentiators attribute set to unverified. MiniMax M3 (MiniMax) possesses Key differentiators attribute set to unverified. Kimi K2.7 (Moonshot AI) possesses Key differentiators attribute set to unverified. Mistral Medium 3.5 (Mistral AI) possesses Key differentiators attribute set to unverified. Each model lists latest version attribute set to the 2026-06-13 landscape entry. The landscape supplies zero verified context-window sizes. The landscape supplies zero verified generation-speed values. The landscape supplies zero verified API-rate-limit values.
The list contains 16 models with their exact 2026-06-13 versions. Pro and Max variants exist alongside standard versions for OpenAI, Anthropic, Google and xAI lines. All pricing values and feature differentiators remain unverified.
GPT-5.5 Pro from OpenAI lists unverified pricing. GPT-5.5 from OpenAI lists unverified pricing. Claude Opus 4.8 from Anthropic lists unverified pricing. Claude Fable 5 from Anthropic lists unverified pricing. Claude Sonnet 4.6 from Anthropic lists unverified pricing. Gemini 3.1 Pro from Google lists unverified pricing. Gemini 3.5 Flash from Google lists unverified pricing. Grok 4.3 from xAI lists unverified pricing. Grok 4.20 from xAI lists unverified pricing. Grok Build CLI from xAI lists unverified pricing. Qwen3.7 Max from Alibaba lists unverified pricing. Qwen qwen3.7-plus from Alibaba lists unverified pricing. DeepSeek V4 Pro from DeepSeek lists unverified pricing. MiniMax M3 from MiniMax lists unverified pricing. Kimi K2.7 from Moonshot AI lists unverified pricing. Mistral Medium 3.5 from Mistral AI lists unverified pricing. Pro and Max variants receive explicit identification separate from standard versions. GPT-5.5 Pro (OpenAI) lists Version attribute set to GPT-5.5 Pro (2026-06-13 landscape). GPT-5.5 (OpenAI) lists Version attribute set to GPT-5.5 (2026-06-13 landscape). Claude Opus 4.8 (Anthropic) lists Version attribute set to Claude Opus 4.8 (2026-06-13 landscape). Claude Fable 5 (Anthropic) lists Version attribute set to Claude Fable 5 (2026-06-13 landscape). Claude Sonnet 4.6 (Anthropic) lists Version attribute set to Claude Sonnet 4.6 (2026-06-13 landscape). Gemini 3.1 Pro (Google) lists Version attribute set to Gemini 3.1 Pro (2026-06-13 landscape). Gemini 3.5 Flash (Google) lists Version attribute set to Gemini 3.5 Flash (2026-06-13 landscape). Grok 4.3 (xAI) lists Version attribute set to Grok 4.3 (2026-06-13 landscape). Grok 4.20 (xAI) lists Version attribute set to Grok 4.20 (2026-06-13 landscape). Grok Build CLI (xAI) lists Version attribute set to Grok Build CLI (2026-06-13 landscape). Qwen3.7 Max (Alibaba) lists Version attribute set to Qwen3.7 Max (2026-06-13 landscape). Qwen qwen3.7-plus (Alibaba) lists Version attribute set to Qwen qwen3.7-plus (2026-06-13 landscape). DeepSeek V4 Pro (DeepSeek) lists Version attribute set to DeepSeek V4 Pro (2026-06-13 landscape). MiniMax M3 (MiniMax) lists Version attribute set to MiniMax M3 (2026-06-13 landscape). Kimi K2.7 (Moonshot AI) lists Version attribute set to Kimi K2.7 (2026-06-13 landscape). Mistral Medium 3.5 (Mistral AI) lists Version attribute set to Mistral Medium 3.5 (2026-06-13 landscape).
Seven models receive a feature table with every column marked unverified. No numeric values for context window size, generation speed or rate limits appear in the source data. Numeric claims are therefore omitted entirely.
| Model | Pricing | Features | Limitations | Best use case | Platform support |
|------------------|-----------|---------------------------|-----------------|--------------------|
| GPT-5.5 Pro | unverified| unverified | unverified | unverified | unverified |
| Claude Opus 4.8 | unverified| unverified | unverified | unverified | unverified |
| Gemini 3.1 Pro | unverified| unverified | unverified | unverified | unverified |
| Grok 4.3 | unverified| unverified | unverified | unverified | unverified |
| Qwen3.7 Max | unverified| unverified | unverified | unverified | unverified |
| DeepSeek V4 Pro | unverified| unverified | unverified | unverified | unverified |
| Kimi K2.7 | unverified| unverified | unverified | unverified | unverified |
The table covers the first seven models by listing order. Remaining models receive identical unverified status across all columns. The comparison omits all numeric claims because the supplied 2026-06-13 landscape contains no verified figures. GPT-5.5 (OpenAI) lists Pricing attribute set to unverified. Claude Fable 5 (Anthropic) lists Pricing attribute set to unverified. Claude Sonnet 4.6 (Anthropic) lists Pricing attribute set to unverified. Gemini 3.5 Flash (Google) lists Pricing attribute set to unverified. Grok 4.20 (xAI) lists Pricing attribute set to unverified. Grok Build CLI (xAI) lists Pricing attribute set to unverified. Qwen qwen3.7-plus (Alibaba) lists Pricing attribute set to unverified. MiniMax M3 (MiniMax) lists Pricing attribute set to unverified. Mistral Medium 3.5 (Mistral AI) lists Pricing attribute set to unverified. GPT-5.5 (OpenAI) lists Features attribute set to unverified. Claude Fable 5 (Anthropic) lists Features attribute set to unverified. Claude Sonnet 4.6 (Anthropic) lists Features attribute set to unverified. Gemini 3.5 Flash (Google) lists Features attribute set to unverified. Grok 4.20 (xAI) lists Features attribute set to unverified. Grok Build CLI (xAI) lists Features attribute set to unverified. Qwen qwen3.7-plus (Alibaba) lists Features attribute set to unverified. MiniMax M3 (MiniMax) lists Features attribute set to unverified. Mistral Medium 3.5 (Mistral AI) lists Features attribute set to unverified.
No independently verified benchmarks exist for brand voice consistency, batch ad generation or Pro versus standard quality differences. Every specific metric remains unverified. Marketers must run direct tests with their own prompts and style guides.
Brand voice consistency receives zero verified scores across the 16 models. Batch ad copy generation receives zero verified throughput numbers. API rate limits and context window sizes receive zero verified values for copywriting workloads. Pro versus standard version quality differences receive zero verified deltas. The ChatGPT vs Claude vs Gemini comparison documents the same absence of copywriting-specific metrics for the current frontier set. Practical testing therefore constitutes the only available evaluation method. GPT-5.5 Pro (OpenAI) receives zero verified brand-voice-consistency score. GPT-5.5 (OpenAI) receives zero verified brand-voice-consistency score. Claude Opus 4.8 (Anthropic) receives zero verified brand-voice-consistency score. Claude Fable 5 (Anthropic) receives zero verified brand-voice-consistency score. Claude Sonnet 4.6 (Anthropic) receives zero verified brand-voice-consistency score. Gemini 3.1 Pro (Google) receives zero verified brand-voice-consistency score. Gemini 3.5 Flash (Google) receives zero verified brand-voice-consistency score. Grok 4.3 (xAI) receives zero verified brand-voice-consistency score. Grok 4.20 (xAI) receives zero verified brand-voice-consistency score. Grok Build CLI (xAI) receives zero verified brand-voice-consistency score. Qwen3.7 Max (Alibaba) receives zero verified brand-voice-consistency score. Qwen qwen3.7-plus (Alibaba) receives zero verified brand-voice-consistency score. DeepSeek V4 Pro (DeepSeek) receives zero verified brand-voice-consistency score. MiniMax M3 (MiniMax) receives zero verified brand-voice-consistency score. Kimi K2.7 (Moonshot AI) receives zero verified brand-voice-consistency score. Mistral Medium 3.5 (Mistral AI) receives zero verified brand-voice-consistency score.
All model selection guidance carries low confidence because pricing, benchmarks and user-reported limitations remain unverified. Power-user and beginner options receive identical unverified status. Teams must evaluate current provider data directly.
Power-user picks reference the 16 models without assigned rankings. Beginner-friendly options reference the same 16 models without assigned rankings. Deal-breakers receive zero verified entries. The Best AI SEO Writing Tools 2026 comparison and the Best AI Blog Writer review both note identical data gaps. Teams therefore obtain current pricing and test outputs against their specific brand guidelines before deployment. GPT-5.5 Pro (OpenAI) receives unverified power-user recommendation status. GPT-5.5 (OpenAI) receives unverified power-user recommendation status. Claude Opus 4.8 (Anthropic) receives unverified power-user recommendation status. Claude Fable 5 (Anthropic) receives unverified power-user recommendation status. Claude Sonnet 4.6 (Anthropic) receives unverified power-user recommendation status. Gemini 3.1 Pro (Google) receives unverified power-user recommendation status. Gemini 3.5 Flash (Google) receives unverified power-user recommendation status. Grok 4.3 (xAI) receives unverified power-user recommendation status. Grok 4.20 (xAI) receives unverified power-user recommendation status. Grok Build CLI (xAI) receives unverified power-user recommendation status. Qwen3.7 Max (Alibaba) receives unverified power-user recommendation status. Qwen qwen3.7-plus (Alibaba) receives unverified power-user recommendation status. DeepSeek V4 Pro (DeepSeek) receives unverified power-user recommendation status. MiniMax M3 (MiniMax) receives unverified power-user recommendation status. Kimi K2.7 (Moonshot AI) receives unverified power-user recommendation status. Mistral Medium 3.5 (Mistral AI) receives unverified power-user recommendation status.
Frequently Asked Questions
Current data provides no verified benchmarks on brand voice consistency. Marketers should test outputs directly with their style guides.
How do API rate limits and context windows affect batch generation of ad copy?
No specific rate limit or context window data is available for copywriting tasks in the 2026 landscape. Practical testing remains necessary.
What is the practical difference in output quality between Pro/Max variants and standard versions?
Differences between Pro/Max and standard models are unverified. Direct comparison testing with your prompts is recommended.
Pricing and value metrics remain unverified across all listed models. Teams should evaluate current pricing directly with providers.
Are there any major limitations reported for these 2026 models in copywriting?
No verified limitations or user complaints specific to copywriting are documented in the supplied data.