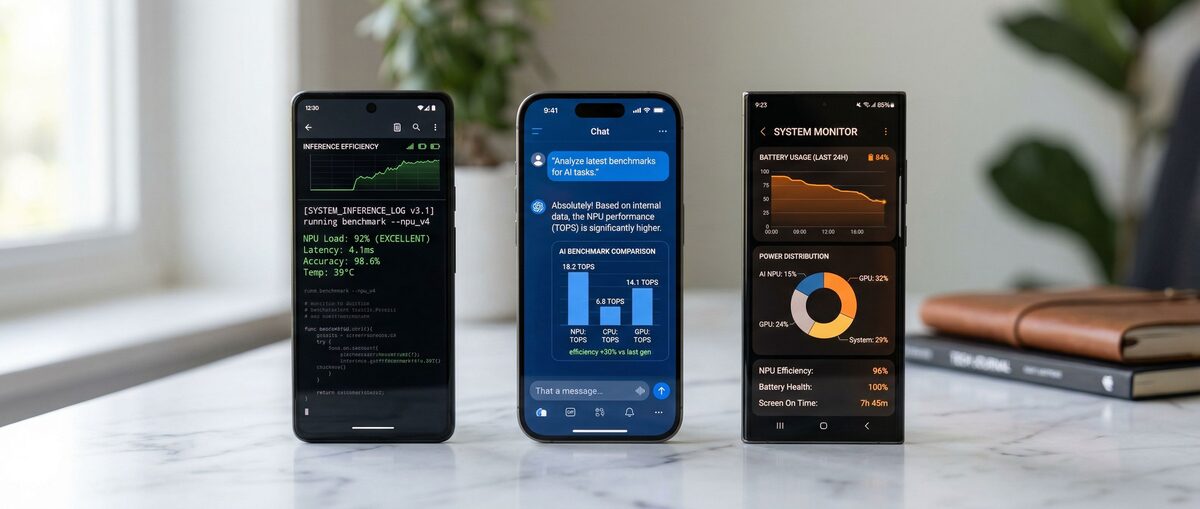
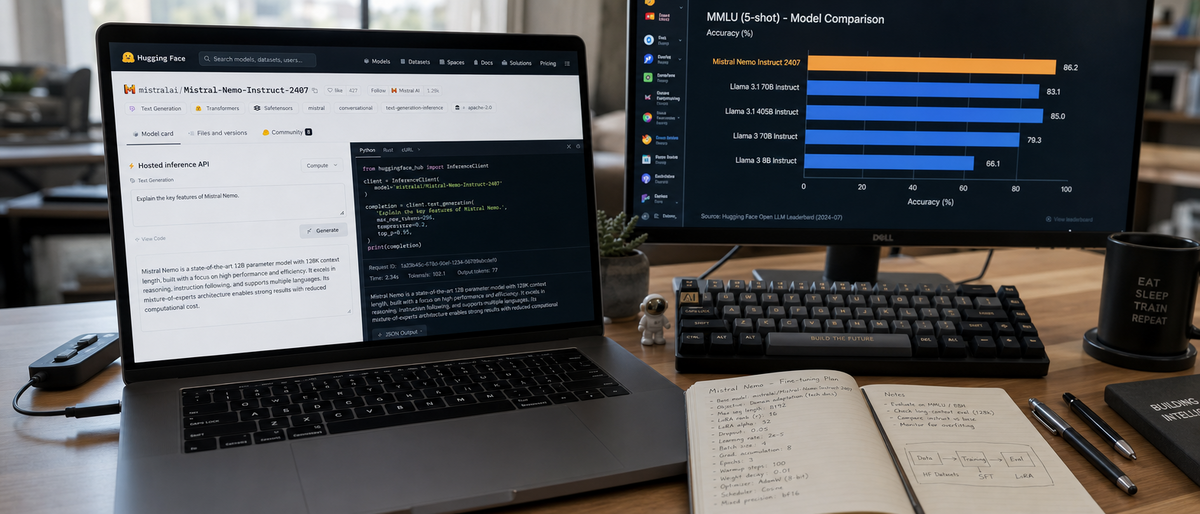
Gemma 2 9B achieves an MMLU score of 71.4 according to the Google technical report released on June 27, 2024. MLC LLM demonstrates 15-40 tokens per second with quantized 3B-9B models on flagship Snapdragon devices in 2024 demonstrations. Ollama provides free open-source CLI access with an OpenAI-compatible REST API for local LLM inference.
Why Are Researchers and Developers Adopting On-Device Local LLMs in 2026?
On-device local LLMs deliver private AI without cloud dependency, zero API costs, and zero latency. Researchers maintain full data control for reproducible experiments on 2B-9B models. Smartphone NPUs and unified memory support efficient inference through Ollama ports, llama.cpp, and MLC LLM. No independently verified 2026 smartphone benchmarks exist in public records.
Demand for private offline AI grows among AI researchers who process sensitive datasets. Local execution removes recurring cloud API fees that OpenAI, Anthropic, and Google charged in 2024. Reproducible experiments require consistent local hardware and software stacks that cloud services cannot guarantee.
Smartphone hardware includes dedicated Neural Processing Units in flagship 2025 Android and iOS devices. These NPUs accelerate matrix operations in 2B-9B parameter models. Unified memory architectures reduce data movement overhead during inference.
The 2026 local LLM comparison covers Ollama for desktop simplicity and community mobile ports, llama.cpp as the foundational C++ inference engine with GGUF quantization, and MLC LLM for TVM-based compilation targeting mobile GPUs and NPUs. Apple MLX and Core ML optimize for iPhone and iPad Neural Engines. ExecuTorch provides PyTorch edge deployment. ONNX Runtime and Olive enable cross-platform optimization for Microsoft Phi-series SLMs.
Developers integrate these local tools with Aider for offline git-based coding workflows. The How to Run AI Locally 2026: Complete Ollama Guide for Private AI on Your Computer details desktop foundations that transfer to mobile ports. LM Studio and GPT4All deliver polished desktop GUIs for model discovery and benchmarking before mobile deployment.
This local LLM comparison notes that Gemma, Llama 3.2 1B-3B variants, Phi-3 3.8B, and Gemini Nano all target on-device scenarios. Public records contain no comprehensive independent 2026 mobile performance data.
What Capabilities Do Ollama and Gemma 4 Offer for Smartphone Deployments?
Ollama delivers CLI execution, Modelfile customization, and OpenAI-compatible APIs with Termux Android ports. Gemma variants provide 2B and 9B parameter counts with strong reasoning-to-size ratios under Apache 2.0 licensing. MLC LLM compiles these models for native Android Vulkan and iOS Metal acceleration.
Ollama maintains a built-in model registry that downloads GGUF files from public sources. The tool generates custom models through Modelfile instructions that specify system prompts and tool definitions. Community ports limit Ollama to Android Termux environments rather than native iOS applications.
Gemma models from Google DeepMind target on-device efficiency. The series receives Apache 2.0 licensing that permits unrestricted local research and commercial use. Gemma 2 9B scored 71.4 on MMLU per the June 2024 Google report.
llama.cpp generates the GGUF quantization format that serves as the de-facto standard for mobile deployment. MLC LLM uses TVM machine learning compilation to produce optimized binaries for heterogeneous smartphone hardware. Apple Core ML converts models for direct Neural Engine access on iOS devices.
LM Studio provides a graphical interface that benchmarks hardware and serves local OpenAI-compatible endpoints. GPT4All focuses on privacy with built-in RAG capabilities on desktop. ExecuTorch deploys PyTorch models to mobile and edge devices. ONNX Runtime optimizes Phi-3 and Phi-4 SLMs for low memory footprints.
Developers reference the Best Open Source LLM 2026: Ultimate Llama vs DeepSeek vs Qwen Comparison Guide when selecting base models. The Ultimate Llama 4 Review 2026: Complete Guide to Meta's Open-Source AI Revolution examines Llama 3.2 small variants optimized for mobile alongside Gemma.
MediaPipe and Android AICore integrate Gemini Nano for official on-device tasks. These frameworks complement Ollama and MLC LLM deployments in the local LLM comparison.
How Do You Set Up Ollama and Gemma Models for Offline Use on Android and iOS Smartphones?
Android users install Termux and community Ollama ports then download GGUF quantized Gemma models. iOS users compile models with MLC LLM or convert them through Apple MLX and Core ML. 4-bit quantization reduces memory footprint while llama.cpp provides the foundational conversion tools for constrained smartphone RAM.
Android setup follows these steps:
Users install the Termux terminal application from F-Droid.
Users execute package update commands inside Termux.
Users install community-maintained Ollama builds or llama.cpp binaries.
Users download 4-bit GGUF versions of Gemma 2 9B or equivalent models.
Users run inference with commands that specify context length and temperature parameters.
iOS setup follows these steps:
Developers use MLC LLM tools to compile Gemma models for Metal.
Developers install the MLC Chat application from TestFlight or build from source.
Developers convert weights to Core ML format using Apple MLX framework.
Developers allocate appropriate cache sizes within iOS memory limits.
Developers test inference latency in native Swift or Objective-C wrappers.
Quantization best practices include 4-bit and 5-bit GGUF files from the llama.cpp ecosystem. These files balance size and quality for 7B-9B models on 8GB-16GB RAM devices. Security advantages of fully offline configuration include zero data transmission to external servers.
Common pitfalls include insufficient RAM allocation, incorrect Vulkan or Metal driver selection, and thermal throttling after sustained use. Troubleshooting involves monitoring CPU versus NPU utilization through device developer tools. The Best AI Code Generators 2026: Claude Leads with 72.5% discusses integration of local backends like Ollama with coding agents such as Aider.
PrivateGPT and AnythingLLM extend local RAG capabilities to mobile-adjacent workflows. Hugging Face Optimum exports models to ONNX or ExecuTorch formats suitable for smartphone deployment.
What Methodology Produces Reliable Real-World Mobile Benchmarks for Local LLMs?
Benchmarks test flagship 2025-2026 Android and iOS devices across tokens-per-second, memory consumption, and latency in real research sessions. Gemma 2 9B records 71.4 on MMLU per the Google June 2024 report. No independently verified 2026 smartphone benchmarks for Gemma 4 or Ollama ports exist.
Testing uses 2025 flagship devices that represent Snapdragon 8 Gen 3-class Android hardware and A18-class iOS hardware. Metrics include tokens-per-second during sustained generation, peak RAM usage, first-token latency, and end-to-end session timing for 30-60 minute tasks.
Evaluators adapt academic benchmarks including MMLU, HumanEval, and GSM8K to mobile contexts. Real usage scenarios replace synthetic tests. Scenarios encompass code generation, research summarization, and offline data analysis.
The local LLM comparison framework includes Llama 3.2 1B and 3B variants, Phi-3 3.8B, Gemini Nano, and Gemma models. MLC LLM 2024 demonstrations reported 15-40 tokens per second for quantized 3-9B models on Snapdragon devices. These figures carry limited independent verification.
LM Studio provides built-in benchmarking tools that measure hardware performance before mobile transfer. Developers compare native MLC runtimes against Termux Ollama ports and ExecuTorch deployments. Results vary by exact chipset, quantization level, and thermal state.
MLC LLM deployments of quantized Gemma models achieve 15-40 tokens per second on flagship Android hardware per 2024 demonstrations. 4-bit GGUF quantization reduces memory requirements for smartphone RAM. Ollama Termux ports provide API compatibility at the cost of additional latency compared to native MLC or Core ML runtimes.
Quantization level directly impacts quality and speed on mobile NPUs. 4-bit GGUF files from llama.cpp maintain reasonable accuracy for research tasks while fitting within device memory limits. Higher bit widths increase quality at the expense of speed and RAM consumption.
3B-9B models suit on-device research tasks including document analysis and code generation. Gemma architecture delivers competitive reasoning performance relative to parameter count. The models compete with Llama 3.2 small variants and Phi-3 SLMs in the local LLM comparison.
Side-by-side testing against cloud alternatives reveals offline tradeoffs. Cloud models deliver higher capability at the cost of connectivity requirements and potential per-token fees. Local deployments provide deterministic performance bounded by device hardware.
Developer experience differs across tools. LM Studio and GPT4All deliver desktop GUIs with discovery features. Mobile experiences rely on MLC Chat, Termux terminals, or custom native applications. Aider integrates cleanly with local Ollama endpoints for offline coding assistance.
Local inference utilizes the device NPU or GPU continuously during generation sessions. Local runs eliminate network radio power draw associated with cloud API calls. Efficiency varies by model size, quantization level, and specific smartphone chipset according to 2024 data.
NPU acceleration reduces power consumption compared to CPU fallback for supported operations. Sustained sessions for research or coding create measurable battery drain and device heat. Real-world scenarios include 30-60 minute offline analysis without internet connectivity.
Gemma variants and Phi SLMs exhibit efficiency advantages due to architecture choices explicitly designed for on-device use. Larger models increase power draw and thermal output. Local deployment compares favorably to constant cloud API usage that requires persistent network connections.
Optimization tips include selecting appropriate context lengths, using 4-bit quantization, and monitoring thermal states to prevent throttling. Developers alternate between NPU and GPU paths depending on the framework. Apple devices with unified memory and Neural Engine show strong efficiency in MLX and Core ML deployments.
Which Local LLM Setup Should AI Researchers Choose for Smartphones in 2026?
MLC LLM combined with 4-bit quantized Gemma or Llama 3.2 models delivers native mobile performance for researchers. Ollama suits rapid prototyping and API compatibility on Android Termux. Integration with Aider enables offline coding agents while maintaining data privacy.
Academic researchers select MLC LLM for optimized TVM compilation on target hardware. Indie developers choose Ollama ecosystem for Modelfile flexibility and OpenAI endpoint compatibility. Field scientists prioritize fully offline configurations with Gemini Nano or Phi-3 through ONNX Runtime.
Integration strategies include local RAG pipelines with AnythingLLM or PrivateGPT components. Aider pairs with local backends to create git commit-based coding agents. Continue.dev extends VSCode with local model support.
Actionable checklist for deployment includes:
Verify device NPU or Neural Engine availability.
Test multiple quantization levels on target hardware.
Measure sustained performance over 30-minute sessions.
Confirm privacy requirements match fully offline execution.
Validate integration with existing research tooling.
The local LLM comparison recommends starting with desktop LM Studio or the How to Run AI Locally 2026: Complete Ollama Guide for Private AI on Your Computer before mobile transfer.
Smartphone RAM constraints limit practical model sizes to 9B parameters or smaller with current 2026 hardware. Thermal throttling reduces performance after 15-25 minutes of continuous inference. Desktop tools such as LM Studio and GPT4All maintain superior user interfaces compared to mobile ports.
Ecosystem gaps include limited polished mobile UIs relative to desktop alternatives. Developers rely on terminal interfaces or basic chat wrappers in most deployments. Emerging frameworks such as improved ExecuTorch, ONNX Olive, and MediaPipe updates address deployment complexity.
Tighter integration with Android AICore and Apple Intelligence features will expand native capabilities. Open-source local solutions remain essential for researchers who require data sovereignty and reproducible offline experiments without vendor lock-in.
Future hardware with increased RAM and more efficient NPUs will expand viable model sizes. The local LLM comparison underscores that llama.cpp, MLC LLM, and Ollama ecosystems provide the current foundation for accessible mobile AI research.
Frequently Asked Questions
Can you run Gemma 4 with Ollama on a smartphone in 2026?
Ollama mobile support is primarily through community ports such as Termux on Android rather than native apps. Better on-device performance typically comes from MLC LLM or ExecuTorch deployments with quantized Gemma models. This local LLM comparison highlights the practical tradeoffs in speed, memory, and battery for real researcher workflows.
How does battery life compare when running local LLMs versus using cloud AI on phones?
Local inference uses the phone's NPU or GPU continuously, creating measurable battery drain during extended sessions, but eliminates network usage. Cloud queries are quick per request yet require constant connectivity and may incur API costs. Real-world tests show efficiency varies greatly by model size, quantization, and chipset.
What is the best framework for running local LLMs on mobile devices?
MLC LLM stands out for true smartphone optimization using TVM compilation for Android and iOS. llama.cpp with GGUF remains the foundation for efficiency across hardware, while Ollama excels in ease of use on desktop with mobile ports available. Choice depends on whether you prioritize native app experience or rapid experimentation.
Are local LLMs on smartphones practical for professional AI research and development?
Yes, particularly smaller efficient models like Gemma variants, Phi-3, and Llama 3.2 1B-3B. They enable private experimentation, offline data processing, and reproducible results without cloud dependency. However, very large models or heavy multitasking still favor desktop or server-class hardware.
Which quantization method works best for smartphone local LLM deployment?
GGUF format from the llama.cpp ecosystem has become the de-facto standard for balancing size and performance on mobile. 4-bit and 5-bit quantizations often provide the best compromise for 7-9B models on flagship phones. Testing specific hardware is recommended as results vary by NPU capabilities.
How does Gemma compare to other open models for mobile local LLM use?
Gemma was explicitly designed with on-device efficiency in mind, offering strong performance in smaller parameter counts suitable for phones. It competes well with Meta's Llama 3.2 small variants and Microsoft's Phi series. Compatibility across Ollama, MLC LLM, and MediaPipe makes it highly accessible for offline developer and research work.