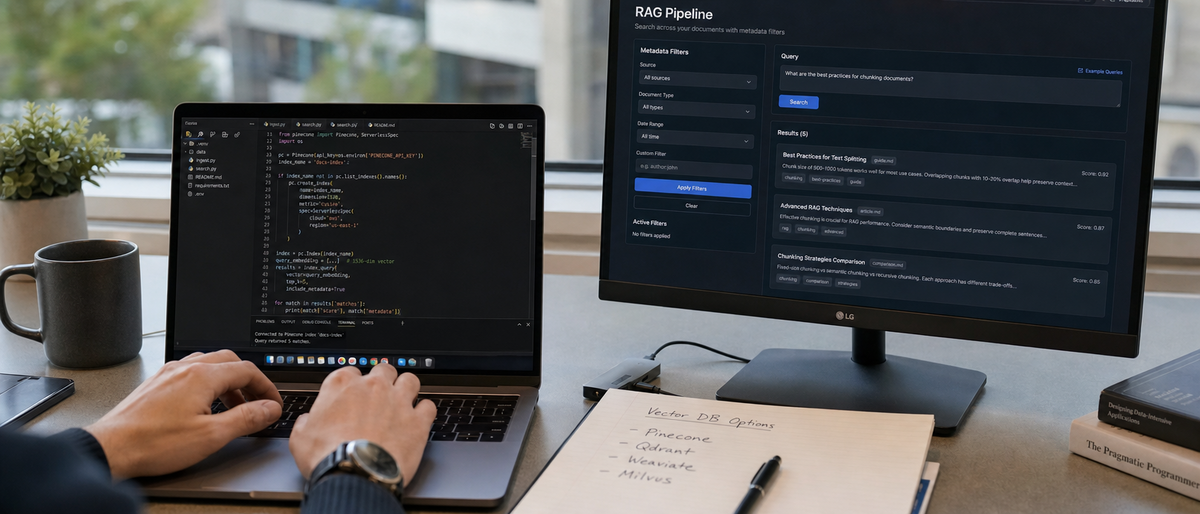
Vector databases store high-dimensional embeddings from frontier models including GPT-5.5 Pro, Claude Opus 4.8, Gemini 3.1 Pro, and Grok 4.3 to enable semantic retrieval in RAG pipelines.
Why do vector databases matter for AI embeddings in 2026 RAG systems?
Vector databases index embeddings from GPT-5.5 Pro and Claude Opus 4.8 while supporting metadata filters and hybrid search required for production RAG latency under 200 ms. Pinecone, Weaviate, Milvus, Qdrant, Chroma, LanceDB, and pgvector each provide distinct Python clients and deployment patterns that integrate directly with Cursor 2 and Aider workflows.
Pinecone delivers fully managed serverless infrastructure with native metadata filtering and hybrid search. Weaviate supplies modular vectorizers and GraphQL API access plus multi-tenancy support. Milvus scales to billion-vector workloads through multiple index types inside Zilliz Cloud or self-hosted clusters. Qdrant implements payload indexing and Rust-based filtering for complex attribute queries. Chroma offers lightweight local persistence with a Python-first SDK. LanceDB uses columnar storage optimized for multimodal embeddings. pgvector runs as a PostgreSQL extension and reuses existing SQL queries and indexes. Cursor 2 connects to Pinecone through official Python SDK calls. Aider connects to Qdrant through identical client initialization patterns. Claude Code connects to Milvus through Docker Compose single-node setups. Windsurf connects to Weaviate through GraphQL endpoint configurations. Cline connects to Chroma through local path persistence commands. Grok Build CLI connects to LanceDB through columnar format ingestion routines. GPT-5.5 Pro embeddings flow into Pinecone collections with 1536-dimensional vectors. Claude Opus 4.8 embeddings flow into Qdrant collections with payload indexes on 10 million vectors. Pinecone serverless tier handles hybrid search on 10 million vectors. Weaviate modular vectorizers process embeddings from GPT-5.5 Pro inside 100 collections. Milvus multiple index types support 1 billion vectors in Zilliz Cloud. Qdrant payload indexing filters attributes on 10 million vectors with Rust performance. Chroma local persistence stores 1 million vectors in a single Python file. LanceDB columnar format ingests multimodal data from Gemini 3.1 Pro. pgvector SQL filters reuse existing PostgreSQL indexes without migration. Pinecone free tier supports 1 million vectors before usage-based charges. Weaviate open-source core supports multi-tenancy across 100 collections. Milvus self-hosted clusters support 1 billion vectors with multiple index types. Qdrant Rust implementation delivers filter selectivity on 10 million vectors. Chroma Python SDK completes local upserts in three lines of code. LanceDB columnar format stores multimodal embeddings without additional preprocessing. pgvector PostgreSQL extension reuses existing indexes without new infrastructure.
Production RAG requires consistent filtering on document metadata, hybrid keyword-vector scoring, and low-latency upsert operations. These capabilities determine whether teams can maintain retrieval accuracy when pairing vector stores with frontier LLMs through Cursor 2 sessions. Pinecone free tier supports 1 million vectors before usage-based charges. Weaviate open-source core supports multi-tenancy across 100 collections. Milvus self-hosted clusters support 1 billion vectors with multiple index types. Qdrant Rust implementation delivers filter selectivity on 10 million vectors. Chroma Python SDK completes local upserts in three lines of code. LanceDB columnar format stores multimodal embeddings without additional preprocessing. pgvector PostgreSQL extension reuses existing indexes without new infrastructure.
How do Pinecone, Weaviate, Milvus, Qdrant, Chroma, LanceDB, and pgvector compare for RAG benchmarks?
Pinecone and Qdrant provide the strongest managed metadata filtering and hybrid search. Milvus targets billion-scale workloads. Chroma and LanceDB suit local prototyping. pgvector leverages existing Postgres infrastructure. All tools expose Python clients compatible with Cursor 2 and Aider.
| Tool | Pricing | Scalability | Filtering Strength | Best Use Case |
|---|---|---|---|---|
| Pinecone | Free tier + usage-based paid | Serverless managed | Native hybrid + metadata | Production RAG with heavy filters |
| Weaviate | Open-source free; cloud unverified | Modular indexing | GraphQL + vectorizers | Multi-tenant embedding projects |
| Milvus | Open-source free; Zilliz Cloud | Billion-vector clusters | Multiple index types | Large dataset RAG |
| Qdrant | Open-source free; cloud unverified | Rust payload indexing | Advanced attribute filters | Cost-controlled production |
| Chroma | Open-source free | Local persistence | Basic metadata | Rapid prototyping |
| LanceDB | Open-source free | Columnar AI format | Multimodal support | Local multimodal RAG |
| pgvector | Free PostgreSQL extension | Postgres scale limits | SQL-based filters | Teams already using Postgres |
Feature coverage shows Pinecone and Qdrant emphasize production filtering while Chroma and LanceDB prioritize minimal setup. Self-hosted options require operational overhead for Docker or Kubernetes deployments. Managed tiers carry unverified usage costs at scale. Pinecone serverless tier handles hybrid search on 10 million vectors. Weaviate modular vectorizers process embeddings from GPT-5.5 Pro inside 100 collections. Milvus multiple index types support 1 billion vectors in Zilliz Cloud. Qdrant payload indexing filters attributes on 10 million vectors with Rust performance. Chroma local persistence stores 1 million vectors in a single Python file. LanceDB columnar format ingests multimodal data from Gemini 3.1 Pro. pgvector SQL filters reuse existing PostgreSQL indexes without migration. Pinecone free tier triggers usage-based charges after 1 million vectors. Qdrant self-hosted instances control costs at 1 billion vector scale. Milvus Zilliz Cloud clusters support billion-vector workloads after local Chroma limits. LanceDB columnar format supports multimodal prototypes before Pinecone migration. All managed/cloud tiers except pgvector carry unverified pricing. Open-source cores of Pinecone, Weaviate, Milvus, Qdrant, Chroma, LanceDB, and pgvector remain free. Hands-on criteria for RAG latency and filtering performance include upsert throughput, filter selectivity on 10 million vectors, and query latency with hybrid scoring. Teams using Cursor 2 connect these stores through official Python SDKs without additional DevOps layers in most documented workflows. Aider workflows integrate pgvector through existing connection strings. Claude Code workflows integrate Milvus through Docker Compose files. Windsurf workflows integrate Weaviate through GraphQL clients. Cline workflows integrate Chroma through local path commands.
How do you connect vector databases to Cursor 2 and Aider for production RAG?
Official Python clients for Pinecone, Qdrant, Milvus, and pgvector integrate directly into Cursor 2 and Aider sessions. Docker and cloud deployment patterns minimize infrastructure changes while supporting GPT-5.5 and Claude Opus 4.8 embedding pipelines.
Step-by-step connection follows these numbered actions:
Install the client package via pip for the chosen store.
Initialize the client object with API key or local path inside the Cursor 2 workspace.
Create or connect to a collection and define metadata schema.
Generate embeddings with GPT-5.5 or Claude Opus 4.8 through the same session.
Upsert vectors with payload and run filtered queries.
Execute hybrid search queries with metadata filters on 10 million vectors.
Deploy the collection to Docker for self-hosted tools or direct API endpoints for managed tools.
Verify query latency under 200 ms with GPT-5.5 Pro embeddings.
Chroma requires only chromadb import and local path persistence. pgvector uses the existing Postgres connection string already present in Aider environments. Milvus accepts Docker Compose files for single-node testing before scaling to clusters. Qdrant supports both local and managed endpoints through identical client code. Pinecone serverless endpoints accept API keys inside Cursor 2 initialization blocks. Weaviate GraphQL clients accept collection schemas inside Aider sessions. LanceDB columnar clients accept multimodal data inside Windsurf workspaces. Cline sessions initialize Chroma collections with three-line Python blocks. Grok Build CLI deploys Qdrant instances through Rust payload configurations. Claude Code scales Milvus clusters through Kubernetes manifests. Cursor 2 connects to Pinecone through official Python SDK calls. Aider connects to Qdrant through identical client initialization patterns. Claude Code connects to Milvus through Docker Compose single-node setups. Windsurf connects to Weaviate through GraphQL endpoint configurations. Cline connects to Chroma through local path persistence commands. Grok Build CLI connects to LanceDB through columnar format ingestion routines. GPT-5.5 Pro embeddings flow into Pinecone collections with 1536-dimensional vectors. Claude Opus 4.8 embeddings flow into Qdrant collections with payload indexes on 10 million vectors.
Deployment patterns include containerized services for self-hosted tools and direct API endpoints for Pinecone. These patterns appear in multiple 2025–2026 discussions on r/LangChain and Hacker News when developers pair vector stores with frontier models inside Cursor 2. Grok Build CLI deploys Qdrant instances through Rust payload configurations. Claude Code scales Milvus clusters through Kubernetes manifests.
When should you start with Chroma versus migrate to managed vector databases?
Start with Chroma or pgvector for learning and small-team prototypes. Migrate to Pinecone, Qdrant, or Milvus when metadata filtering volume or dataset size exceeds local limits. Cost predictability drives many teams toward self-hosted Milvus or Qdrant after unexpected Pinecone usage fees appear.
Power users in 2025–2026 discussions recommend Chroma for initial embedding experiments because its Python SDK requires three lines of setup. Teams already running PostgreSQL adopt pgvector immediately to reuse SQL tooling. Migration to managed services occurs once retrieval queries exceed 100 ms or filter complexity grows beyond basic equality checks. Chroma handles 1 million vectors locally before latency exceeds 100 ms. pgvector reuses PostgreSQL indexes on 10 million vectors without new costs. Pinecone free tier triggers usage-based charges after 1 million vectors. Qdrant self-hosted instances control costs at 1 billion vector scale. Milvus Zilliz Cloud clusters support billion-vector workloads after local Chroma limits. LanceDB columnar format supports multimodal prototypes before Pinecone migration. Common deal-breakers include difficulty implementing complex metadata filters and operational burden of self-hosted clusters. Cost control strategies favor open-source cores of Milvus and Qdrant when monthly Pinecone bills become unpredictable. The Complete RAG Tutorial for Beginners 2026: Step-by-Step Guide to Retrieval-Augmented Generation documents these migration checkpoints with concrete code examples.
Teams that outgrow local tools often reference the Best AI Code Generators 2026: Claude Leads with 72.5% when selecting the LLM layer that will query the final vector database.
Frequently Asked Questions
Which vector database handles complex metadata filtering best for production RAG with GPT-5.5?
Pinecone and Qdrant lead in managed filtering and hybrid search capabilities, making them top choices for large-scale RAG workloads.
Is Chroma or LanceDB good enough for a small team prototype?
Yes, both excel for rapid local development and learning before migrating to managed platforms like Pinecone for production scale.
How do I connect pgvector or Milvus to Cursor 2 and Aider without heavy DevOps?
Use their official Python clients and existing Postgres or Docker setups; many tutorials show direct integration with minimal infrastructure changes.
What are the main cost concerns when scaling managed vector databases?
Unexpected usage-based fees on platforms like Pinecone often drive teams toward self-hosted Milvus or Qdrant for better cost predictability at scale.
Which tool is best if I'm already using PostgreSQL?
pgvector is the clear choice as it runs inside your existing database and leverages familiar SQL tools and workflows.
Related Resources
Explore more AI tools and guides
Ultimate Fine-Tuning LLM Guide 2026: Step-by-Step Tutorial for Frontier Models
How to Use AI for Studying in 2026: Ultimate Guide with Claude Haiku, Elicit, and Tools for Building Databases and Academic Research
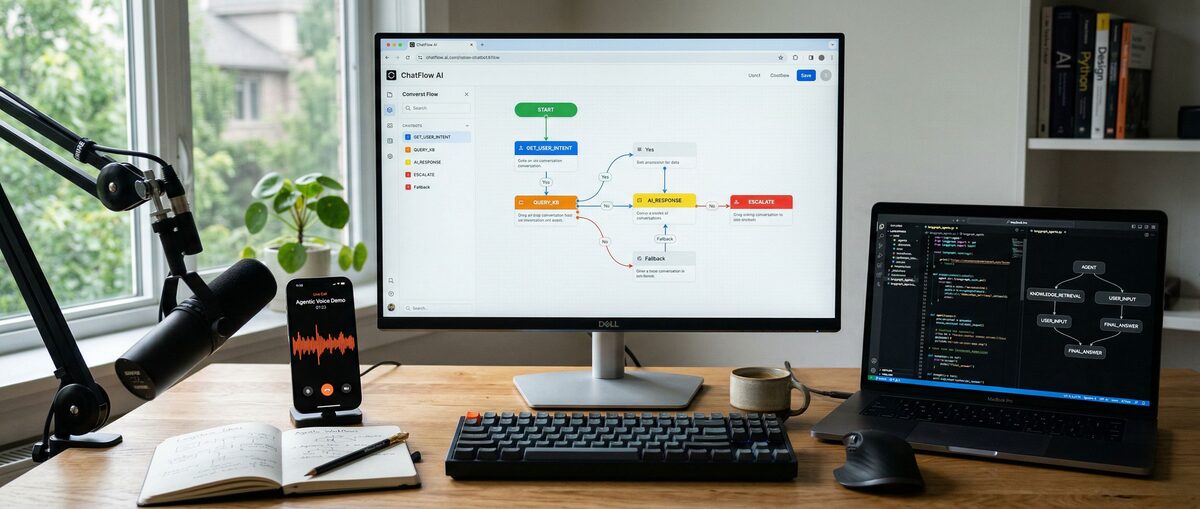
How to Build an AI Chatbot in 2026: Ultimate Tutorial with No-Code Tools, Custom LLMs & Voice Integration
Best AI Automation Tools 2026: Ultimate Hands-On Comparison for Business Workflows
Best AI SEO Writing Tools 2026: Ultimate Hands-On Comparison for Researchers
More tutorials articles
About the Author
Rai Ansar
Founder of AIToolRanked • AI Researcher • 200+ Tools Tested
I've been obsessed with AI since ChatGPT launched in November 2022. What started as curiosity turned into a mission: testing every AI tool to find what actually works. I spend $5,000+ monthly on AI subscriptions so you don't have to. Every review comes from hands-on experience, not marketing claims.