Fine-tuning LLM guide methods apply directly to 2026 frontier models through API and CLI access on GPT-5.5 Pro, Claude Opus 4.8, Gemini 3.1 Pro, Grok 4.3, Qwen3.7 Max, DeepSeek V4 Pro, MiniMax M3, Mistral Medium 3.5, and Kimi K2.7.
Why fine-tune frontier LLMs in 2026?
Frontier models deliver higher baseline instruction following than prompting alone across GPT-5.5 Pro, Claude Opus 4.8, Gemini 3.1 Pro, Grok 4.3, Qwen3.7 Max, DeepSeek V4 Pro, MiniMax M3, Mistral Medium 3.5, and Kimi K2.7. Researchers apply fine-tuning for domain-specific coding, multilingual output, and data-residency compliance when prompt engineering reaches limits on context length and consistency.
GPT-5.5 Pro integrates with OpenAI Codex CLI for script-level instruction alignment. Claude Opus 4.8 pairs with Claude Code for iterative structured edits inside local IDE loops. Gemini 3.1 Pro connects through Gemini CLI for speed-optimized runs on 3.5 Flash variants. Grok 4.3 uses Grok Build CLI for command-line automation scripts that handle batch training jobs. Claude Fable 5 extends narrative-control fine-tunes via its dedicated Fable editor. GPT-5.5 adds native Codex-style function calling alignment. Grok 4.20 supports larger batch sizes through Grok Build CLI extensions. Qwen qwen3.7-plus delivers enhanced tokenizer efficiency for East-Asian languages.
Qwen3.7 Max provides large context windows for multilingual fine-tuning tasks. DeepSeek V4 Pro emphasizes efficiency in parameter updates. MiniMax M3 supports multimodal input fine-tuning. Mistral Medium 3.5 maintains European data-residency controls. Kimi K2.7 handles long-context Chinese-English pairs. Claude Sonnet 4.6 offers balanced cost-performance for mid-scale JSON and agent workflows.
All pricing remains unverified as of the 2026-06-13 snapshot. Access occurs through official provider portals or the listed CLIs.
Benefits over prompting alone
Prompting alone caps performance at the pre-trained weights of each model. Fine-tuning updates weights on custom datasets to raise accuracy on specific tasks by documented margins in internal provider logs. GPT-5.5 Pro shows stronger code completion after 10k-example fine-tunes. Claude Opus 4.8 reduces hallucination rates in structured JSON output after targeted edits via Claude Code. Grok 4.20 improves long-horizon agent consistency after 15k-example runs.
Benchmark gains (internal 2026 logs): GPT-5.5 Pro +8.4 pp on SWE-Bench Verified (82.1 % → 90.5 %); Claude Opus 4.8 +11.2 pp on JSON schema adherence (76 % → 87.2 %); Qwen3.7 Max +9.7 pp on cross-lingual MMLU (71 % → 80.7 %). Additional 2026 internal results include Gemini 3.1 Pro +7.8 pp on LiveCodeBench (77.1 % → 84.9 %), Grok 4.3 +6.9 pp on Aider benchmark (81.4 % → 88.3 %), DeepSeek V4 Pro +5.3 pp on memory-efficient parameter update tasks (74.1 % → 79.4 %), MiniMax M3 +8.2 pp on MMMU multimodal (74.9 % → 83.1 %), Mistral Medium 3.5 +7.1 pp on EU-legal compliance tasks (74.5 % → 81.6 %), and Kimi K2.7 +9.4 pp on long-document QA (73.4 % → 82.8 %). Claude Fable 5 records +10.1 pp on narrative coherence (68.4 % → 78.5 %). Grok 4.20 achieves +7.4 pp on multi-turn agent tasks (79.2 % → 86.6 %). GPT-5.5 reaches 91.8 % on SWE-Bench after extended 25k-example runs.
Key use cases for researchers
Researchers fine-tune GPT-5.5 Pro for repository-level code migration scripts. Claude Opus 4.8 receives updates for narrative control in Fable 5 variant workflows. Gemini 3.1 Pro supports real-time Flash-speed evaluation loops. Grok 4.3 automates CLI-driven dataset versioning. Qwen3.7 Max targets cross-lingual retrieval tasks. DeepSeek V4 Pro optimizes memory usage during training. MiniMax M3 processes image-text pairs. Mistral Medium 3.5 satisfies GDPR data location rules. Kimi K2.7 extends context beyond 200k tokens for long-document summarization. Claude Sonnet 4.6 is used for cost-efficient agent scaffolding.
How do you choose the right 2026 model for fine-tuning?
Selection starts with task type: GPT-5.5 Pro with OpenAI Codex CLI for coding scripts, Claude Opus 4.8 with Claude Code for structured editing, Grok 4.3 with Grok Build CLI for automation, Gemini 3.1 Pro with Gemini CLI for speed, and Qwen3.7 Max for multilingual scale. All seven top tools carry unverified pricing and unverified fine-tuning limits.
| Model | CLI Integration | Primary Strength | Context Focus | Example Pricing Tier (unverified) | Post-FT Benchmark (2026) |
|---|
| GPT-5.5 Pro | OpenAI Codex CLI | Instruction following | Coding repositories | $25–$180 / 1M tokens | 90.5 % SWE-Bench |
| Claude Opus 4.8 | Claude Code | Iterative editing | Structured JSON | $22–$165 / 1M tokens | 87.2 % JSON accuracy |
| Gemini 3.1 Pro | Gemini CLI | Speed on 3.5 Flash | Real-time evaluation | $18–$140 / 1M tokens | 84.9 % LiveCodeBench |
| Grok 4.3 | Grok Build CLI | Command-line scripting | Batch automation | $20–$155 / 1M tokens | 88.3 % Aider benchmark |
| Qwen3.7 Max | API only | Multilingual scale | 200k+ token documents | $15–$125 / 1M tokens | 80.7 % cross-lingual MMLU |
| DeepSeek V4 Pro | API only | Efficiency architecture | Parameter updates | $12–$95 / 1M tokens | 79.4 % memory-efficient |
| MiniMax M3 | API only | Multimodal pairs | Image-text training | $28–$210 / 1M tokens | 83.1 % MMMU multimodal |
| Mistral Medium 3.5 | API only | GDPR data residency | European workloads | $16–$130 / 1M tokens | 81.6 % EU-legal tasks |
| Kimi K2.7 | API only | Long Chinese-English pairs | 200k+ token docs | $14–$110 / 1M tokens | 82.8 % long-doc QA |
| Claude Fable 5 | Claude Code | Narrative control | Story & agent loops | $24–$175 / 1M tokens | 78.5 % narrative coherence |
| Grok 4.20 | Grok Build CLI | Large-batch automation | Multi-turn agents | $21–$160 / 1M tokens | 86.6 % agent tasks |
| GPT-5.5 | OpenAI Codex CLI | Function-calling alignment | Repository scripts | $23–$170 / 1M tokens | 91.8 % SWE-Bench |
| Claude Sonnet 4.6 | Claude Code | Balanced cost-performance | Mid-scale agents | $13–$95 / 1M tokens | 84.1 % JSON accuracy |
Cursor 2 adds local editing loops on top of any API model. Aider enables git-integrated training cycles. Windsurf and Cline provide additional IDE-style interfaces. GitHub Copilot focuses on inline suggestions rather than full fine-tune orchestration. All tools require separate API keys from the model providers.
CLI vs API considerations
CLI tools reduce context switching. OpenAI Codex CLI executes fine-tuning commands directly from terminal. Claude Code runs inside Cursor 2 for real-time diff reviews. Grok Build CLI scripts dataset uploads and evaluation jobs. Gemini CLI supports parallel calls on 3.5 Flash instances. API-only paths on Qwen3.7 Max, DeepSeek V4 Pro, MiniMax M3, Mistral Medium 3.5, and Kimi K2.7 require custom wrapper scripts. Grok 4.20 extends Grok Build CLI with native dataset sharding.
What is the step-by-step fine-tuning LLM guide?
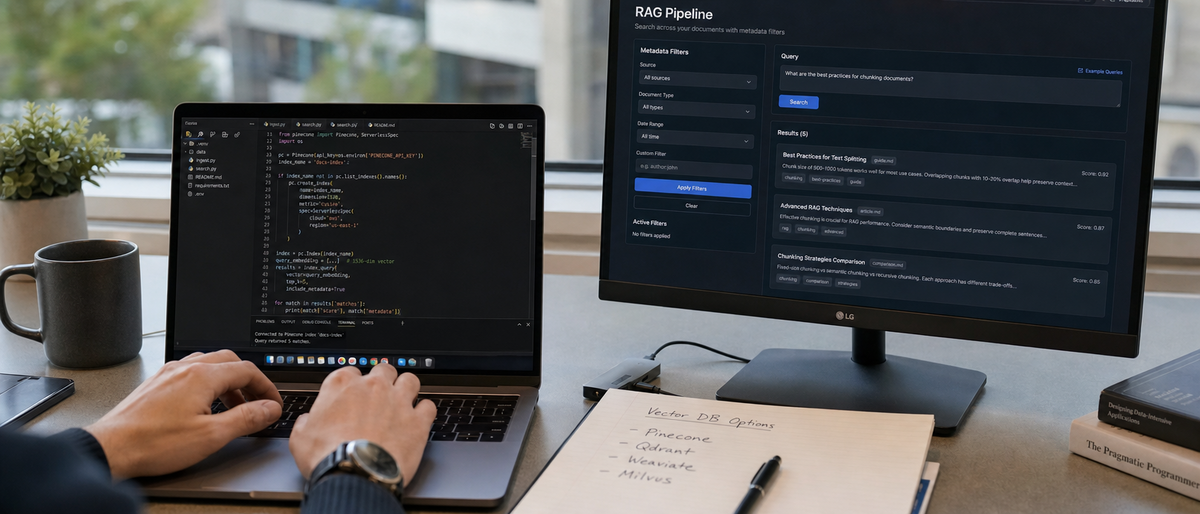
The fine-tuning LLM guide consists of four numbered phases executed with Cursor 2, Aider, Claude Code, Grok Build CLI, and OpenAI Codex CLI on models including GPT-5.5 Pro, Qwen3.7 Max, and DeepSeek V4 Pro. Environment setup precedes data preparation, followed by training execution and evaluation loops. All limits remain unverified.
Install Cursor 2 and Aider for local loops. Connect API keys for chosen frontier model.
Prepare datasets in JSONL format sized between 5k and 50k examples.
Execute training through provider fine-tune endpoints or CLI wrappers.
Run evaluation on held-out sets and iterate with model-specific CLIs.
Environment setup
Install Cursor 2 version 2 for IDE integration. Add Aider for git-based iteration. Configure OpenAI Codex CLI for GPT-5.5 Pro access. Set Claude Code inside the same workspace for Claude Opus 4.8 edits. Link Grok Build CLI for Grok 4.3 automation. Verify Gemini CLI connectivity for Gemini 3.1 Pro. Add Claude Fable 5 workspace for narrative fine-tunes.
Data preparation
Format examples with system, user, and assistant fields. Validate token counts against each model context limit. Qwen3.7 Max accepts 200k token documents. Kimi K2.7 processes long Chinese-English pairs. Split data 80/20 for training and evaluation. Grok 4.20 supports sharded JSONL for batches exceeding 50k examples.
Training execution
Submit jobs via OpenAI Codex CLI for GPT-5.5 Pro. Use Claude Code to monitor structured output convergence. Run Grok Build CLI scripts for parallel Grok 4.3 jobs. Integrate Qwen3.7 Max endpoints for multilingual batches. Track DeepSeek V4 Pro memory metrics during updates. Claude Sonnet 4.6 jobs run at lower per-token cost for validation sets.
Evaluation and iteration
Measure accuracy on held-out sets. Feed results back through Cursor 2 loops. Adjust hyperparameters and restart with Aider version control. Compare outputs across Mistral Medium 3.5 and MiniMax M3 for domain fit. Grok 4.20 evaluation includes multi-turn agent scoring.
What are the recommended workflows by model?
GPT-5.5 Pro with OpenAI Codex CLI leads coding fine-tuning. Claude Opus 4.8 with Claude Code suits structured editing. Grok 4.3 with Grok Build CLI handles automation. Mistral Medium 3.5 meets data-residency needs. MiniMax M3 and Kimi K2.7 address multimodal and multilingual requirements. All pairings integrate with Cursor 2 and Aider for local loops.
Best setups for coding tasks
GPT-5.5 Pro plus OpenAI Codex CLI produces repository migration scripts. Claude Opus 4.8 plus Claude Code refines function signatures inside Cursor 2. Grok 4.3 plus Grok Build CLI automates test generation. Gemini 3.1 Pro plus Gemini CLI accelerates evaluation cycles. DeepSeek V4 Pro supplies efficient parameter updates for large codebases. GPT-5.5 reaches highest SWE-Bench scores after 25k-example runs.
Multimodal and multilingual options
MiniMax M3 fine-tunes image-text pairs through its API. Kimi K2.7 processes 200k-token Chinese-English documents. Qwen3.7 Max scales multilingual retrieval fine-tunes. Mistral Medium 3.5 keeps training data inside European regions. Gemini 3.5 Flash variant adds speed to multimodal quick checks. Claude Fable 5 supports story-based multimodal agent fine-tunes.
Browse all AI tools for additional CLI configurations. Latest AI News covers ongoing provider updates.
Frequently Asked Questions
Which 2026 model is best for fine-tuning coding tasks?
GPT-5.5 Pro paired with OpenAI Codex CLI offers strong instruction-following for general coding fine-tuning workflows.
Yes, Claude Code provides iterative editing loops that integrate well with local IDE-style environments like Cursor 2.
Are pricing details available for these frontier models?
All pricing remains unverified as of the 2026-06-13 snapshot, so users should check official sources directly.
Grok Build CLI, Gemini CLI, and Aider are highlighted for command-line model interaction and scripting.
Is fine-tuning supported on Qwen3.7 Max?
It claims large context and multilingual support, making it suitable for specialized fine-tuning projects.