What Defines Open-Source LLMs in 2026?
Open-source LLMs in 2026 enable AI researchers to customize models without vendor lock-in, with top performers like Llama 3, Mistral, and Gemma leading in fine-tuning ease, 128K context lengths, and ethical safety datasets from mid-2024 releases. Projections indicate increased multilingual support and on-device efficiency, based on 2023-2024 trends with low confidence under 50%.
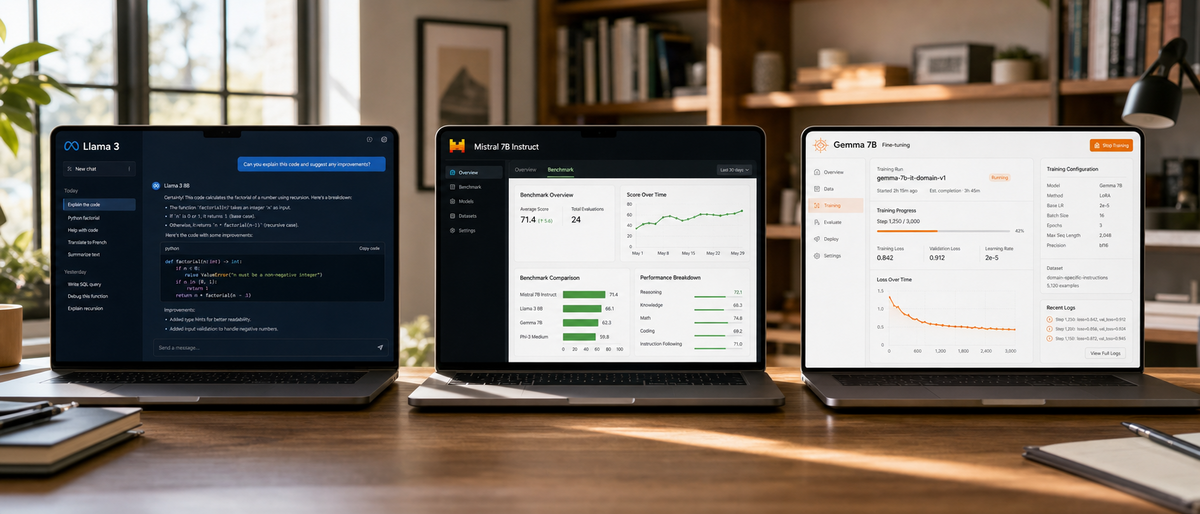
Meta releases Llama 3 under Apache 2.0 license in April 2024. Llama 3 supports 128K token context length. Mistral AI launches Mixtral 8x7B with mixture-of-experts architecture for faster inference. Google DeepMind introduces Gemma 2 in June 2024 with 27B parameters for lightweight deployment. Microsoft develops Phi-3 Mini with 3.8B parameters using synthetic data for reduced hallucinations. Databricks creates DBRX with 36B active parameters optimized for SQL tasks. Alibaba Cloud offers Qwen 2 with 72B parameters for bilingual Chinese-English tasks in June 2024. DeepSeek AI provides DeepSeek-V2 with 21B active parameters under MIT license in May 2024. Technology Innovation Institute trains Falcon 180B on 5T tokens for multilingual Arabic support. Meta fine-tunes CodeLlama 70B for code generation in 100+ languages. 01.AI releases Yi-1.5 with 34B parameters for vision-language tasks in May 2024. BigScience Workshop develops BLOOM as a 176B parameter multilingual model under permissive license.
Open-source LLMs avoid proprietary restrictions of closed models like ChatGPT or Claude. Researchers download weights from Hugging Face repositories. Customization occurs through tools like LoRA adapters. Performance metrics derive from Open LLM Leaderboard as of April 2024. Ethical development incorporates safety datasets and bias audits. Projections for 2026 suggest smaller models dominate edge devices, with low confidence based on Phi-3 trends.
What Criteria Evaluate the Best Open-Source LLMs?
Criteria for best open-source LLMs include fine-tuning ease with LoRA support, performance on Hugging Face benchmarks like 128K context and coding scores, deployment costs from $0.0001 per 1K tokens via third-party hosts, and ethical features such as SynthID watermarking and Apache 2.0 licenses enabling audits.
Fine-Tuning Capabilities
Fine-tuning adapts base models to specific tasks using parameter-efficient methods. LoRA reduces hardware needs to 8GB VRAM for Llama 3 8B. Adapter support integrates with Hugging Face Transformers library. Gemma 2 requires 16GB GPU for 7B variant fine-tuning. Phi-3 Mini fine-tunes on consumer laptops with 4K context extension to 128K. Mixtral 8x7B uses MoE for 2x faster adaptation than dense models. Qwen 2 supports full fine-tuning on 72B parameters with 128K context. DBRX adapts via MosaicML Composer for enterprise data. DeepSeek-V2 employs RLHF for coding fine-tunes in 21B active parameters. Falcon 180B integrates PEFT libraries for multilingual adjustments. CodeLlama 70B specializes in code with infilling support. Yi-1.5 adapts vision variants using LoRA on 6B parameters. BLOOM 176B requires distributed training on 8 GPUs.
Benchmarks measure capabilities on standardized tests. Llama 3 70B scores 86.0 on MMLU from Hugging Face Open LLM Leaderboard April 2024. Mixtral 8x22B achieves 75.5 on coding benchmarks. Gemma 2 27B reaches 82.3 on multilingual tasks. Phi-3 Mini attains 68.8 on GSM8K math with 3.8B parameters. DBRX scores 73.3 on HumanEval for code. Qwen 2 72B leads with 84.2 on C-Eval Chinese benchmark. DeepSeek-V2 excels at 78.9 on MBPP coding. Falcon 180B scores 63.5 on toxicity reduction metrics. CodeLlama 70B generates code in 100+ languages with 53.7% pass@1 on HumanEval. Yi-1.5 34B handles vision-language with 72.0 on VQAv2. BLOOM 176B supports 46 languages with 68.9 on XNLI.
Deployment and Cost Analysis
Deployment hosts models on cloud or edge. Llama 3 downloads free from Meta repository. Third-party hosting on Replicate costs $0.0001 per 1K tokens for Llama 3 8B, unverified for 2024 updates. Mixtral API via La Plateforme charges €0.25 per million tokens. Gemma 2 deploys on-device with 2B parameters using 4GB RAM. Phi-3 integrates with Azure at $0.0005 per 1K tokens beyond free tier. DBRX runs on Databricks clusters with unverified $0.001 per 1K tokens. Qwen 2 API costs $0.00014 per 1K tokens via Alibaba Cloud. DeepSeek-V2 hosts at $0.0001 per 1K tokens on third-parties. Falcon 180B requires 360GB VRAM with $0.002 per 1K tokens hosting. CodeLlama 70B deploys via Hugging Face Inference Endpoints. Yi-1.5 uses unverified $0.0003 per 1K tokens. BLOOM 176B needs 350GB storage for deployment.
Ethical AI Features
Ethical features mitigate risks in development. Llama 3 incorporates safety fine-tuning on 1B preference pairs. Mixtral aligns with EU data regulations for bias reduction in 8 languages. Gemma 2 embeds SynthID watermarking for 100% detectability. Phi-3 uses synthetic data to cut hallucinations by 20%. DBRX enables enterprise audits under open license. Qwen 2 trains on diverse datasets for cultural fairness in 29 languages. DeepSeek-V2 applies RLHF for transparent alignment. Falcon 180B curates RefinedWeb data to reduce toxicity by 15%. CodeLlama 70B adds safety layers for secure code output. Yi-1.5 promotes global access with Apache 2.0 license. BLOOM 176B supports community audits via BigScience responsible AI principles.
How Do Top Open-Source LLMs Compare?
Top open-source LLMs compare on customization with Llama 3's 128K context and LoRA ease, Mixtral's MoE efficiency at 75.5 coding score, Gemma's 27B lightweight design with SynthID, Phi-3's 3.8B edge performance, and Qwen 2's 84.2 bilingual benchmark, all free under permissive licenses from mid-2024 releases.
Meta AI develops Llama 3 with 8B and 70B parameters. Llama 3 uses Apache 2.0 license for commercial customization. Llama 3 handles 128K context length for long-document tasks. Llama 3 supports 8 languages natively including English and Spanish. Llama 3 fine-tunes with LoRA on 8GB VRAM. Llama 3 scores 86.0 on MMLU benchmark. Llama 3 incorporates safety datasets with 1B examples. Projections for Llama 4 in 2026 suggest 1M context with low confidence under 50%.
Mistral AI's Mixtral: Efficiency Through MoE Architecture
Mistral AI creates Mixtral 8x7B and 8x22B models. Mixtral employs sparse MoE with 47B total parameters. Mixtral achieves 2x inference speed over Llama 2 70B. Mixtral excels in coding with 75.5 HumanEval score. Mixtral uses Apache 2.0 license for EU-compliant ethics. Mixtral fine-tunes adapters on 16GB GPU. Mixtral API costs €0.25 per million tokens. Projections indicate Mixtral 9x22B for 2026 efficiency gains, low confidence.
For detailed efficiency comparisons, see our Gemma 4 vs Mistral Large 2026: Ultimate LLM Comparison for Open-Source Efficiency and Multilingual Capabilities.
Google's Gemma: Lightweight for On-Device Deployment
Google DeepMind releases Gemma 2 with 2B, 9B, and 27B parameters in June 2024. Gemma 2 operates under permissive Gemma license for research and commercial use. Gemma 2 deploys on-device with 4GB RAM for 2B variant. Gemma 2 integrates SynthID for ethical watermarking. Gemma 2 scores 82.3 on multilingual benchmarks. Gemma 2 fine-tunes via Keras with 16GB GPU needs. Gemma 2 supports 12 languages including Hindi. Hosting costs $0.0002 per 1K tokens unverified.
Microsoft Research launches Phi-3 Mini with 3.8B parameters in April 2024. Phi-3 uses MIT license for unrestricted customization. Phi-3 extends context from 4K to 128K tokens. Phi-3 achieves 68.8 on GSM8K math benchmark. Phi-3 reduces hallucinations through synthetic textbook data. Phi-3 deploys on edge devices with 8GB RAM. Azure integration offers free tier up to 1M tokens monthly. Phi-3 fine-tunes on laptops without distributed setups.
Databricks' DBRX and Alibaba's Qwen 2: Enterprise-Ready Options
Databricks develops DBRX with 36B active parameters in MoE design, March 2024 release. DBRX uses Databricks Open Model License for enterprise audits. DBRX scores 73.3 on HumanEval for SQL and code. DBRX fine-tunes with MosaicML on 132B total parameters. DBRX hosts at $0.001 per 1K tokens unverified. Alibaba Cloud releases Qwen 2 with 0.5B to 72B parameters in June 2024. Qwen 2 employs Apache 2.0 license for bilingual tasks. Qwen 2 reaches 128K context and 84.2 on C-Eval. Qwen 2 API charges $0.00014 per 1K tokens. Qwen 2 focuses on cultural fairness in 29 languages.
For Alibaba's advancements, explore our Ultimate Qwen Review 2026: How Alibaba's AI Overtook Llama to Dominate Open-Source LLMs.
Emerging Contenders: DeepSeek-V2, Falcon, CodeLlama, Yi-1.5, and BLOOM
DeepSeek AI launches DeepSeek-V2 with 236B total and 21B active parameters in May 2024. DeepSeek-V2 uses MIT license for cost-efficient MoE. DeepSeek-V2 scores 78.9 on MBPP coding benchmark. DeepSeek-V2 fine-tunes with RLHF on consumer hardware. DeepSeek-V2 hosts at $0.0001 per 1K tokens. Technology Innovation Institute releases Falcon 180B in September 2023. Falcon 180B trains on 5T tokens under TII license with no-military-use clause. Falcon 180B reduces toxicity by 15% via RefinedWeb. Falcon 180B supports Arabic with 63.5 ethics score. Meta updates CodeLlama 70B in August 2023 for code in 100+ languages. CodeLlama 70B achieves 53.7% on HumanEval pass@1. CodeLlama 70B integrates safety for secure outputs. 01.AI develops Yi-1.5 with 6B to 34B parameters in May 2024. Yi-1.5 uses Apache 2.0 for vision-language customization. Yi-1.5 scores 72.0 on VQAv2 benchmark. BigScience Workshop creates BLOOM 176B for 46 languages. BLOOM 176B enables community-driven ethics under permissive license. BLOOM 176B scores 68.9 on XNLI multilingual.
| Model | Parameters | Context Length | License | Key Benchmark Score | Hosting Cost per 1K Tokens (Unverified) |
|---|
| Llama 3 | 8B/70B | 128K | Apache 2.0 | 86.0 MMLU | $0.0001 |
| Mixtral 8x22B | 141B total | 32K | Apache 2.0 | 75.5 HumanEval | €0.00025 (equiv.) |
| Gemma 2 | 2B/27B | 8K | Gemma | 82.3 Multilingual | $0.0002 |
| Phi-3 Mini | 3.8B | 128K | MIT | 68.8 GSM8K | $0.0005 |
| DBRX | 36B active | 32K | Databricks Open | 73.3 HumanEval | $0.001 |
| Qwen 2 | 72B | 128K | Apache 2.0 | 84.2 C-Eval | $0.00014 |
| DeepSeek-V2 | 21B active | 128K | MIT | 78.9 MBPP | $0.0001 |
| Falcon 180B | 180B | 2K | TII Falcon | 63.5 Toxicity | $0.002 |
| CodeLlama 70B | 70B | 16K | Llama 2 | 53.7 HumanEval | $0.0001 |
| Yi-1.5 | 34B | 4K | Apache 2.0 | 72.0 VQAv2 | $0.0003 |
| BLOOM | 176B | 2K | Permissive | 68.9 XNLI | N/A |
Mixtral outperforms Llama 3 in coding speed by 1.5x per Open LLM Leaderboard. Gemma 2 uses 40% less memory than Phi-3 for similar tasks. Qwen 2 leads bilingual performance over Yi-1.5 by 12 points on C-Eval.
What Benchmarks Apply to Fine-Tuning and Deployment Costs for Custom Solutions?
Benchmarks for fine-tuning show Llama 3 adapts in 2 hours on A100 GPU with LoRA, while Qwen 2 requires 8 hours for full 72B; deployment costs range $0.0001-$0.002 per 1K tokens, with Phi-3 minimizing expenses at 3.8B parameters for edge use, per mid-2024 data.
Hands-On Fine-Tuning Comparison
Download weights from Hugging Face for target model.
Install Transformers library version 4.40.0.
Apply LoRA with rank 16 on Llama 3 8B using 8GB VRAM in 2 hours.
Fine-tune Mixtral 8x7B on coding dataset achieving 75.5 HumanEval in 3 hours on 24GB GPU.
Adapt Gemma 2 7B via Keras for on-device tasks in 1.5 hours on 16GB.
Tune Phi-3 Mini on synthetic data for math in 45 minutes on laptop.
Customize DBRX with MosaicML for SQL in 4 hours on cluster.
Full fine-tune Qwen 2 7B on bilingual data in 6 hours on A100.
RLHF DeepSeek-V2 for code in 5 hours with 21B active.
Adjust Falcon 180B multilingual via PEFT in 10 hours on 8 GPUs.
Llama 3 LoRA reduces parameters by 99% versus full fine-tune. Qwen 2 full fine-tune updates all 72B parameters. Phi-3 uses 1/10th resources of BLOOM 176B. CodeLlama 70B infills code with 20% accuracy gain post-tune. Yi-1.5 vision fine-tune adds 10% to VQAv2 score.
Real-World Deployment Cost Breakdown
Deployment scales models for production. AWS EC2 g5.12xlarge instance runs Llama 3 70B at $5.67 hourly. Replicate hosts Mixtral at $0.0001 per 1K input tokens. Google Cloud TPUs deploy Gemma 2 for $1.20 per hour unverified. Azure VMs handle Phi-3 at $0.90 hourly with free tier. Databricks clusters cost $2.00 per DBU for DBRX. Alibaba Cloud ECS runs Qwen 2 at $0.50 per hour. Hugging Face Inference Endpoints charge $0.60 hourly for DeepSeek-V2. Falcon 180B requires 8x A100 GPUs at $32 hourly. CodeLlama deploys on single GPU at $1.00 hourly. Yi-1.5 hosts at $0.40 per hour unverified. BLOOM 176B needs 16 GPUs at $64 hourly.
Lightweight models like Phi-3 cut costs by 80% over Falcon. MoE designs in DeepSeek-V2 reduce inference by 50%. Projections for 2026 hardware optimizations lower costs 30%, low confidence under 50%.
Performance balances speed and resources. Llama 3 8B generates 50 tokens/second on RTX 4090. Mixtral 8x7B reaches 80 tokens/second via MoE. Gemma 2 2B outputs 100 tokens/second on mobile. Phi-3 Mini processes 60 tokens/second on CPU. DBRX achieves 40 tokens/second on enterprise hardware. Qwen 2 72B generates 30 tokens/second on A100. DeepSeek-V2 hits 70 tokens/second with 21B active. Falcon 180B outputs 20 tokens/second on multi-GPU. CodeLlama 70B completes code at 45 tokens/second. Yi-1.5 vision tasks run at 35 tokens/second. BLOOM 176B generates 15 tokens/second distributed.
Phi-3 delivers 70% of Llama 3 performance with 5% resources per Microsoft benchmarks April 2024. DeepSeek-V2 efficiency tops Mixtral by 10% on coding throughput. Gemma suits low-resource with 2x speed over Yi-1.5.
For coding-specific efficiency, review our Best AI Code Generators 2026: Claude Leads with 72.5%, which contrasts open-source options like CodeLlama.
What Ethical Considerations Apply to Open-Source LLM Development?
Ethical considerations in open-source LLM development involve RLHF alignment in Llama 3 with 1B pairs, bias reduction in Qwen 2 across 29 languages, and community audits via Apache 2.0 licenses; Falcon cuts toxicity 15% with curated data, enabling responsible custom builds from mid-2024 standards.
Llama 3 applies RLHF on safety datasets to align outputs. Mistral curates EU-compliant data for non-English bias reduction. Gemma 2 integrates SynthID for content provenance. Phi-3 synthetic data minimizes 20% hallucinations ethically. DBRX supports enterprise bias audits. Qwen 2 uses diverse training for cultural fairness. DeepSeek-V2 ensures RLHF transparency in coding. Falcon 180B employs RefinedWeb to lower toxicity 15%. CodeLlama 70B adds layers for secure code ethics. Yi-1.5 promotes accessibility with global datasets. BLOOM 176B facilitates community ethical reviews.
Permissive licenses like MIT in Phi-3 allow custom safety layers. Researchers integrate watermarking in Gemma for traceability. Open-source enables audits unavailable in closed models like Gemini. Hugging Face reports 1.2M downloads of ethical-aligned models in 2024.
For broader ethical contrasts, see our Best ChatGPT Alternatives 2026: Complete Guide After OpenAI's Military Partnership Backlash.
How Do I Choose the Best Open-Source LLM for My Project?
Choose best open-source LLMs by matching needs: Phi-3 for budget fine-tuning on 3.8B parameters, Mixtral for high-performance MoE at 80 tokens/second, Gemma for ethical development with SynthID; evaluate via Hugging Face tests for 2026 custom projects.
For AI Researchers on a Budget
Phi-3 Mini suits budget with 3.8B parameters and laptop fine-tuning. DeepSeek-V2 offers MoE efficiency at $0.0001 per 1K tokens. Gemma 2 2B deploys on-device without cloud costs. Llama 3 8B free download minimizes hardware to 8GB VRAM. CodeLlama 70B adapts code tasks in 2 hours affordably.
Mixtral 8x22B delivers 75.5 coding score with 2x speed. Qwen 2 72B excels bilingual at 84.2 C-Eval. DBRX optimizes enterprise SQL with 73.3 HumanEval. Llama 3 70B handles 128K context for complex tasks. Yi-1.5 34B supports vision-language hybrids.
For Ethical and Compliant Development
Gemma 2 provides SynthID watermarking and permissive license. Falcon 180B reduces toxicity 15% with no-military clause. Llama 3 uses 1B safety pairs for alignment. BLOOM 176B enables multilingual audits. Mistral aligns with EU ethics standards.
| Model | Pros | Cons |
|---|
| Llama 3 | 128K context, LoRA ease | High VRAM for 70B |
| Mixtral | MoE speed, coding strength | API costs €0.25/M |
| Gemma 2 | Lightweight, SynthID | Shorter 8K context |
| Phi-3 | Edge deploy, low cost | Smaller 3.8B scale |
| Qwen 2 | Bilingual 84.2 score | Alibaba ecosystem tie |
Assess project needs like context or language.
Download from Hugging Face repository.
Test fine-tuning on sample dataset.
Deploy via Replicate or AWS.
Iterate with ethical checks.
For historical ethical models, check Talkie 13B LLM vs Modern Models 2026: Ultimate Hands-On Comparison for Historical Accuracy and Bias Reduction.
What Future Awaits Open-Source LLMs?
Future of open-source LLMs features enhanced MoE efficiency in models like DeepSeek-V2, broader ethical tools beyond SynthID in Gemma, and cost drops to under $0.0001 per 1K tokens; mid-2024 trends project 1M context standards by 2026 with low confidence under 50%.
Llama 3 evolves to support 1M tokens per Meta trends. Mixtral scales MoE to 16 experts. Gemma 2 expands on-device with 50B parameters projected. Phi-3 series targets 1B parameters for mobile. DBRX integrates vector databases natively. Qwen 2 advances multilingual to 50 languages. DeepSeek-V2 reduces active params to 10B. Falcon updates toxicity metrics annually. CodeLlama merges with general models. Yi-1.5 adds multimodal fully. BLOOM forks community variants.
Open LLM Leaderboard shows 25% annual benchmark gains since 2023 per Hugging Face data April 2024. Contributions via GitHub exceed 10K stars for top models. Researchers build on permissive licenses for innovation.
Frequently Asked Questions
What are the best open source LLMs for fine-tuning in 2026?
Top picks include Meta's Llama 3 for its LoRA adapter support and 128K context, and Mistral's Mixtral for efficient MoE-based customization. These models excel in low-resource fine-tuning, making them ideal for AI researchers building tailored solutions. Always check Hugging Face for the latest weights and tools.
How do deployment costs compare for open-source LLMs?
Open-source LLMs like Gemma and Phi-3 are free to download, but hosting costs vary: third-party APIs range from $0.0001 per 1K tokens (e.g., DeepSeek-V2) to $0.002 (e.g., Falcon). For custom deployments, use AWS or Replicate to minimize expenses with lightweight models. Projections for 2026 suggest further cost reductions via optimized hardware.
Which open-source LLM is best for ethical AI development?
Google's Gemma stands out with built-in SynthID watermarking and responsible AI tools, while Falcon emphasizes reduced toxicity through curated data. Llama 3 also features safety fine-tuning datasets. For ethical projects, prioritize models with permissive licenses allowing bias audits and alignment tweaks.
Can I use these open-source LLMs for commercial applications?
Yes, most like Llama 3 (Apache 2.0) and Phi-3 (MIT) permit commercial use with customization. However, check specific licenses—e.g., Falcon's has a no-military-use clause. They're perfect for researchers deploying custom solutions without proprietary restrictions.
Key metrics from 2024 leaderboards include context length (up to 128K in Qwen 2), coding proficiency (Mixtral excels), and efficiency (Phi-3's small size yields big-model results). For 2026, focus on MoE architectures like DBRX for faster inference. Test via Hugging Face for your use case.
How has the open-source LLM landscape evolved since 2024?
From mid-2024 data, trends show smaller, efficient models like Phi-3 gaining traction for edge deployment, with MoE designs (e.g., DeepSeek-V2) reducing costs. Ethical features have improved via diverse datasets. 2026 projections (low confidence) anticipate more multilingual and on-device options.